

OCR(光学字符识别)能够从图片中识别并提取文本内容。此功能适用于将用户上传的照片中的文字转换为可编辑的文本格式,提高数据处理的效率和准确性。OCR 节点可以识别终端用户上传的图片信息,并提取出每张图片中的文本内容,以列表的形式输出给下游消费。应用场景示例:
- 场景 1:翻译外文文献
您需要翻译一篇包含外文(如德文)的学术论文。利用 OCR 功能识别外文文本,并使用翻译工具进行翻译。
- 场景 2:识别证件类图片信息
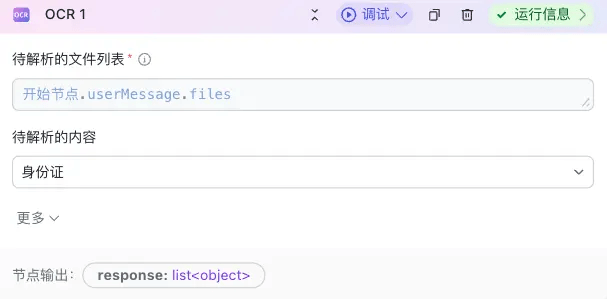
帮助用户识别身份证、营业执照等卡证图片上有效信息,并对有效信息和关键字段进行结构化提取。
使用说明
参数说明
返回值
Response:list<string> 类型,执行成功时,节点会返回图片识别结果的列表(存在多张图片识别场景)
使用示例
- 通过 OCR 识别图片中的产品信息
- 250px|700px|reset
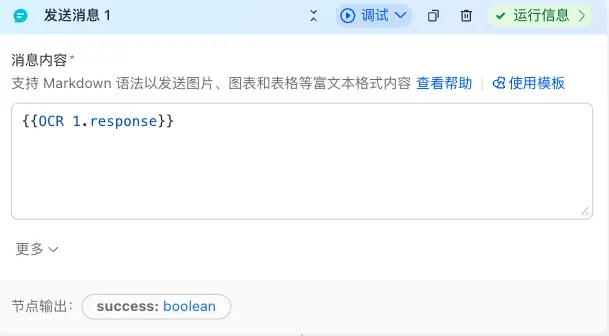
2.消息内容直接引用大模型的文本输出,通过发送消息节点发送给终端用户提取出的结构化信息
250px|700px|reset









