

评测功能 定义
「评测管理」可用于搭建评测集,批量评测开发态、运行态的AI应用,产出真实的使用效果。同时,可根据业务需要灵活选择应用评测维度,支持全应用(端到端模式)、问答等。评测日志结果支持在线人工评估,或导出后进一步分析。
目前在线人工评估的选项主要针对知识问答或工作流中调度了知识问答的应用。
评测操作指南
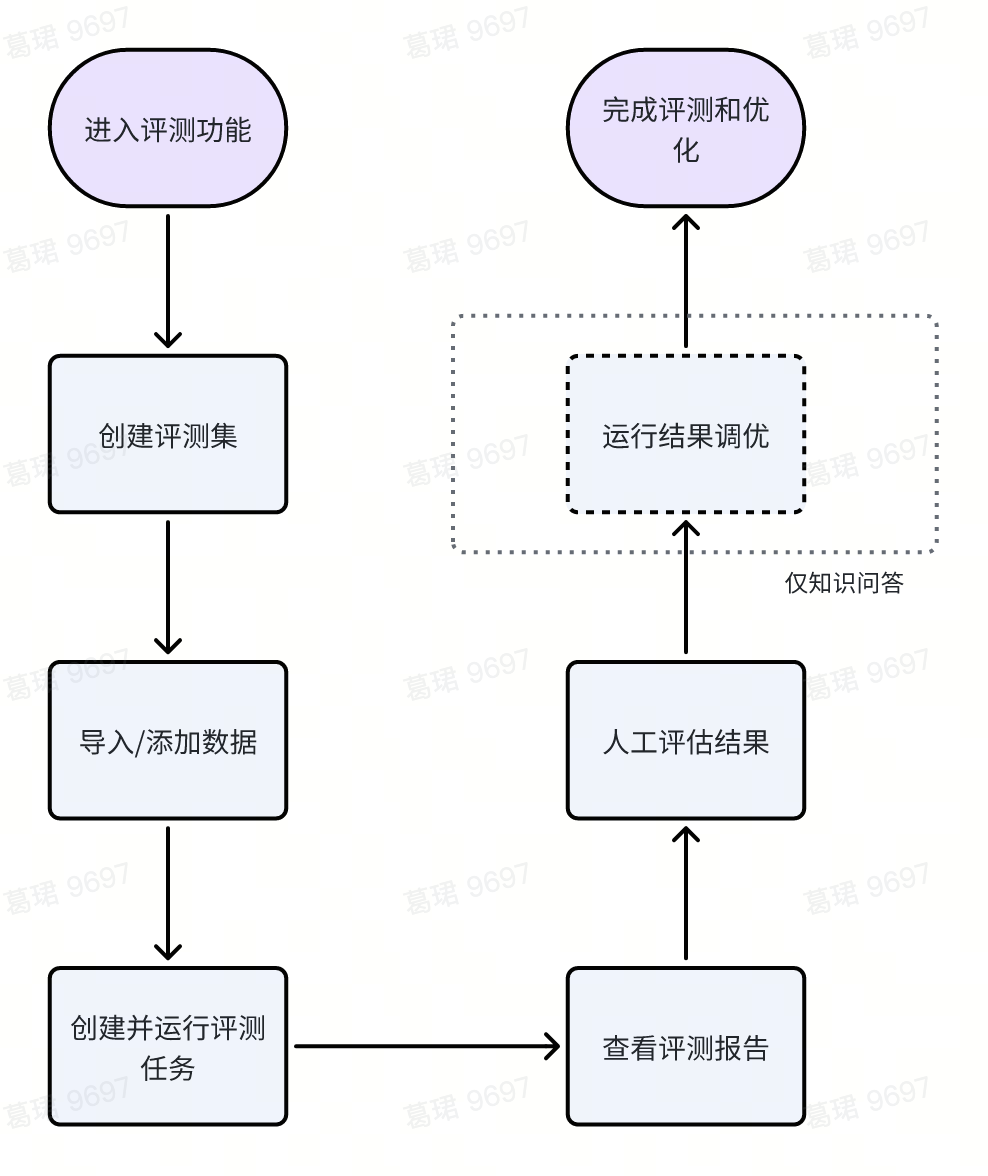
整体流程:
250px|700px|reset
Step1:创建并导入评测集
创建评测集并导入评测数据,支持通过批量上传或者逐条添加的方式;
250px|700px|reset 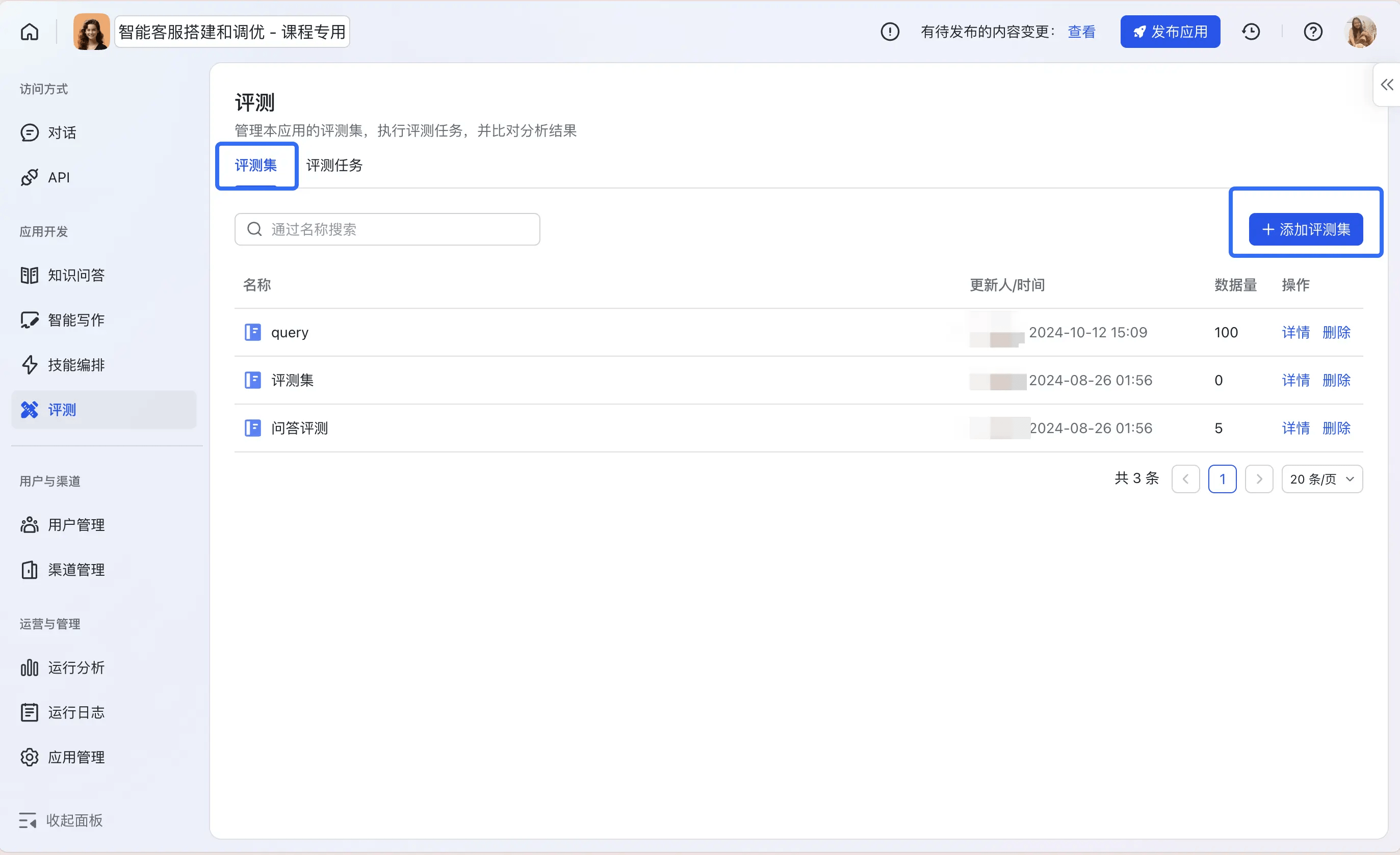 | 250px|700px|reset 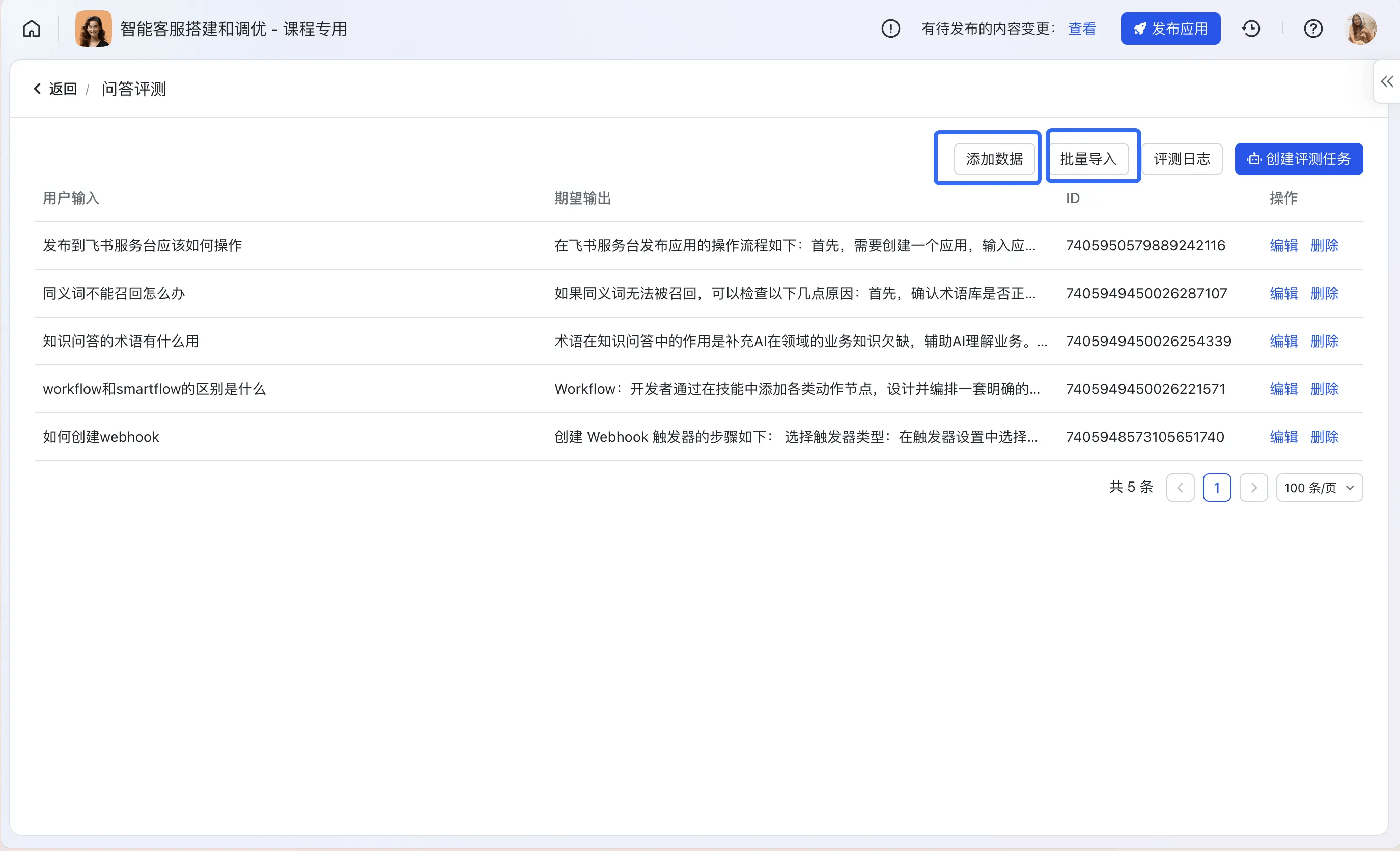 |
Step2:创建评测任务
基于评测集可以进行跑批,支持选择评测环境、评测范围;
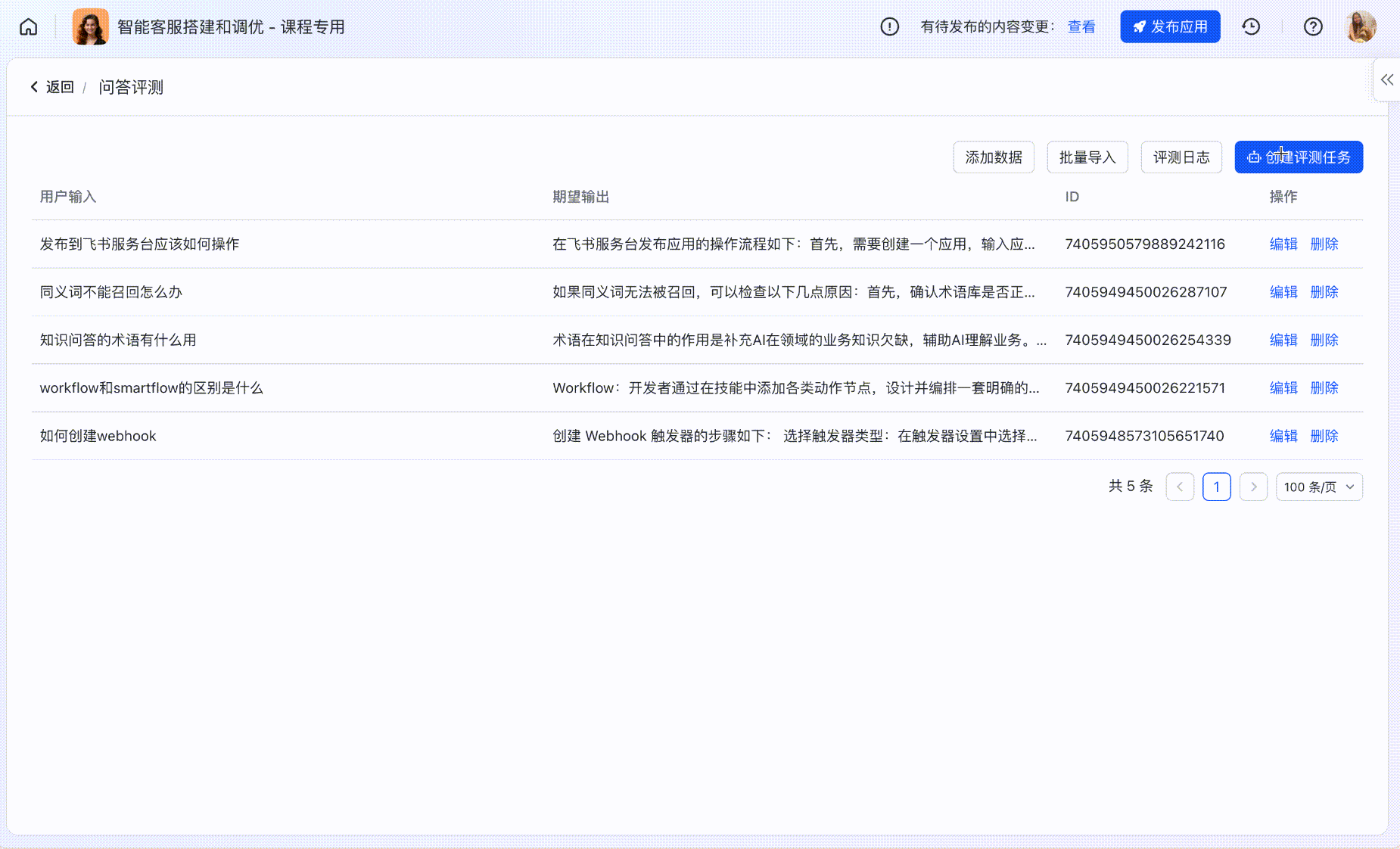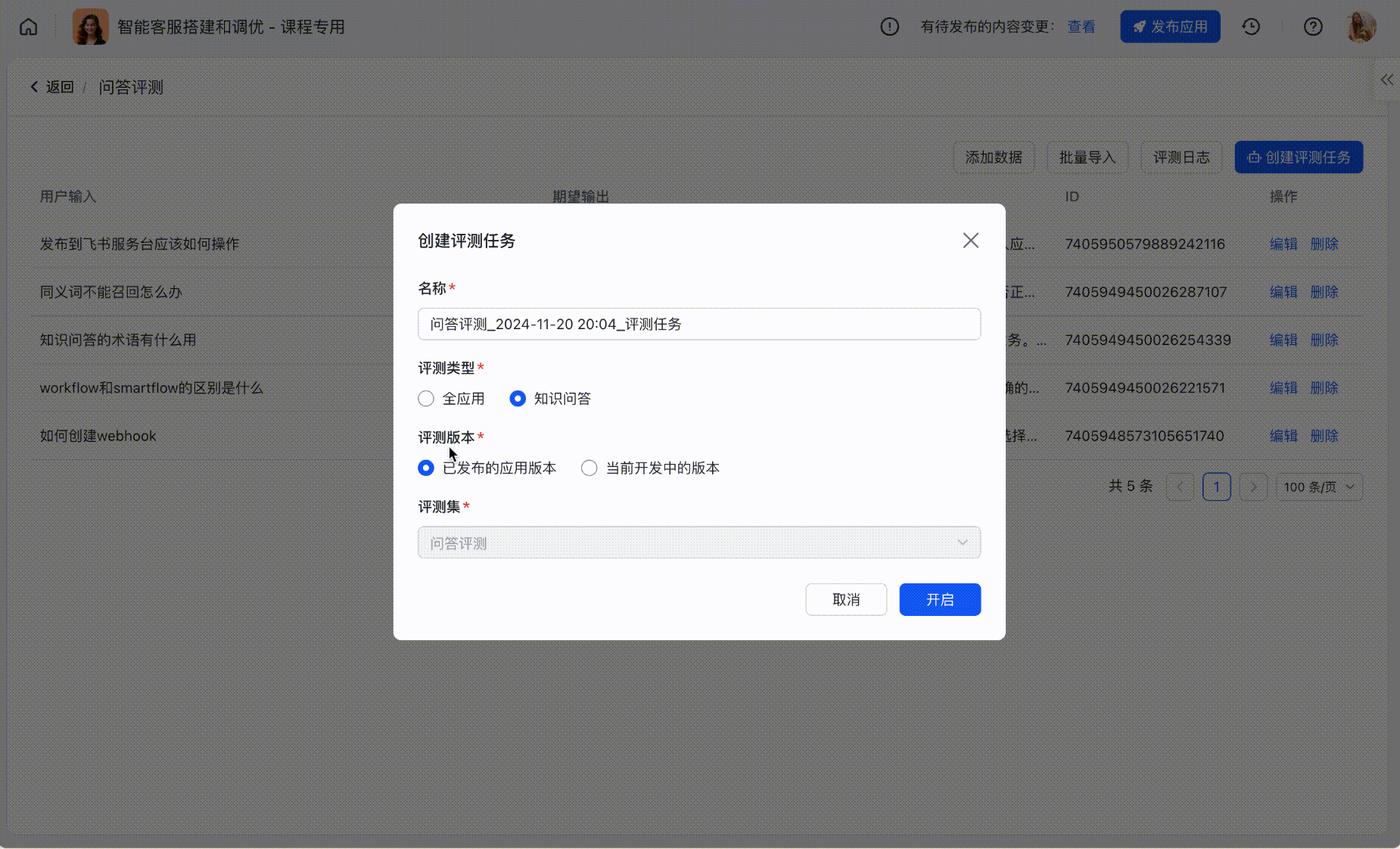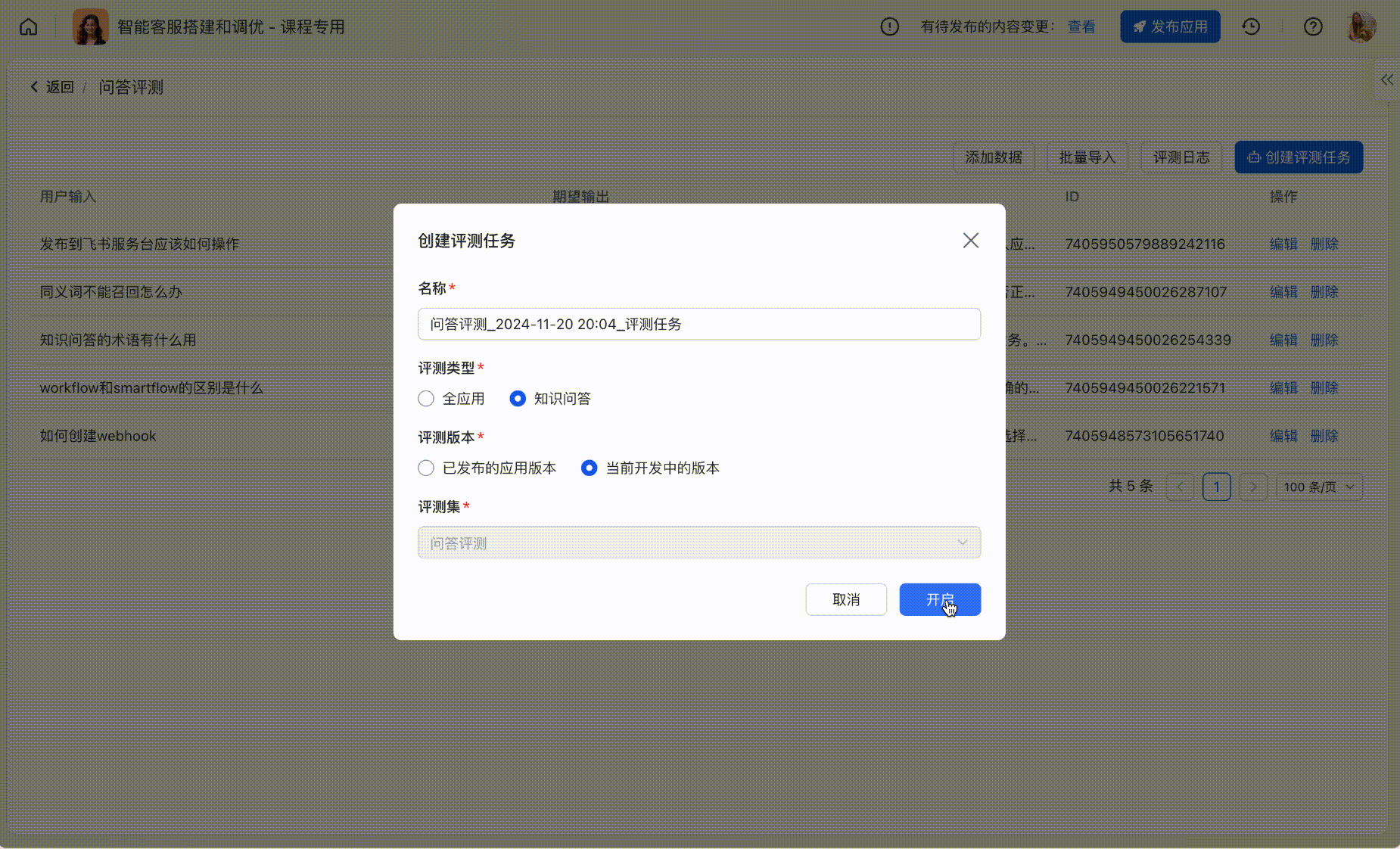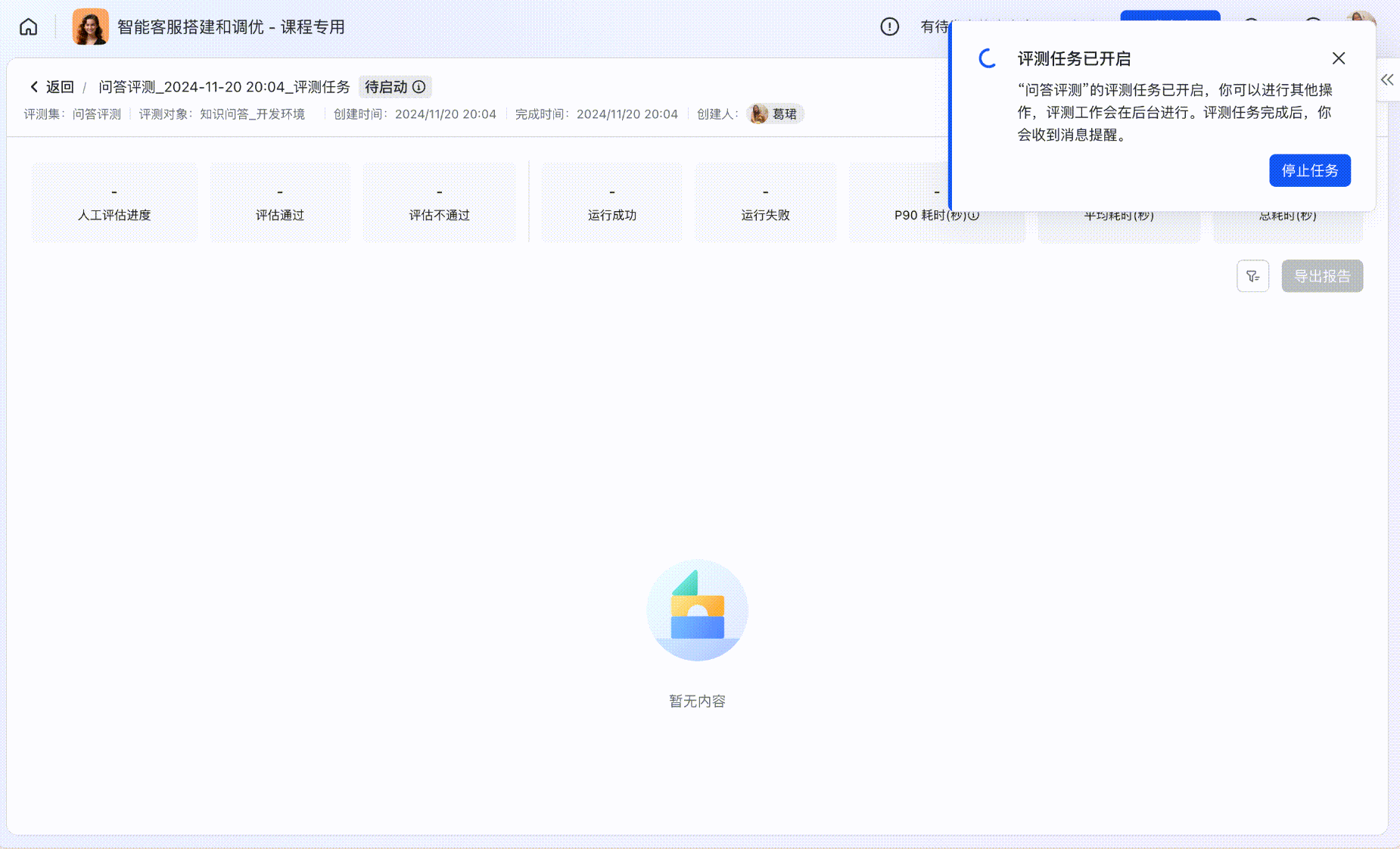
250px|700px|reset
也可在「评测任务」标签下,创建新的评测任务并选择评测集:
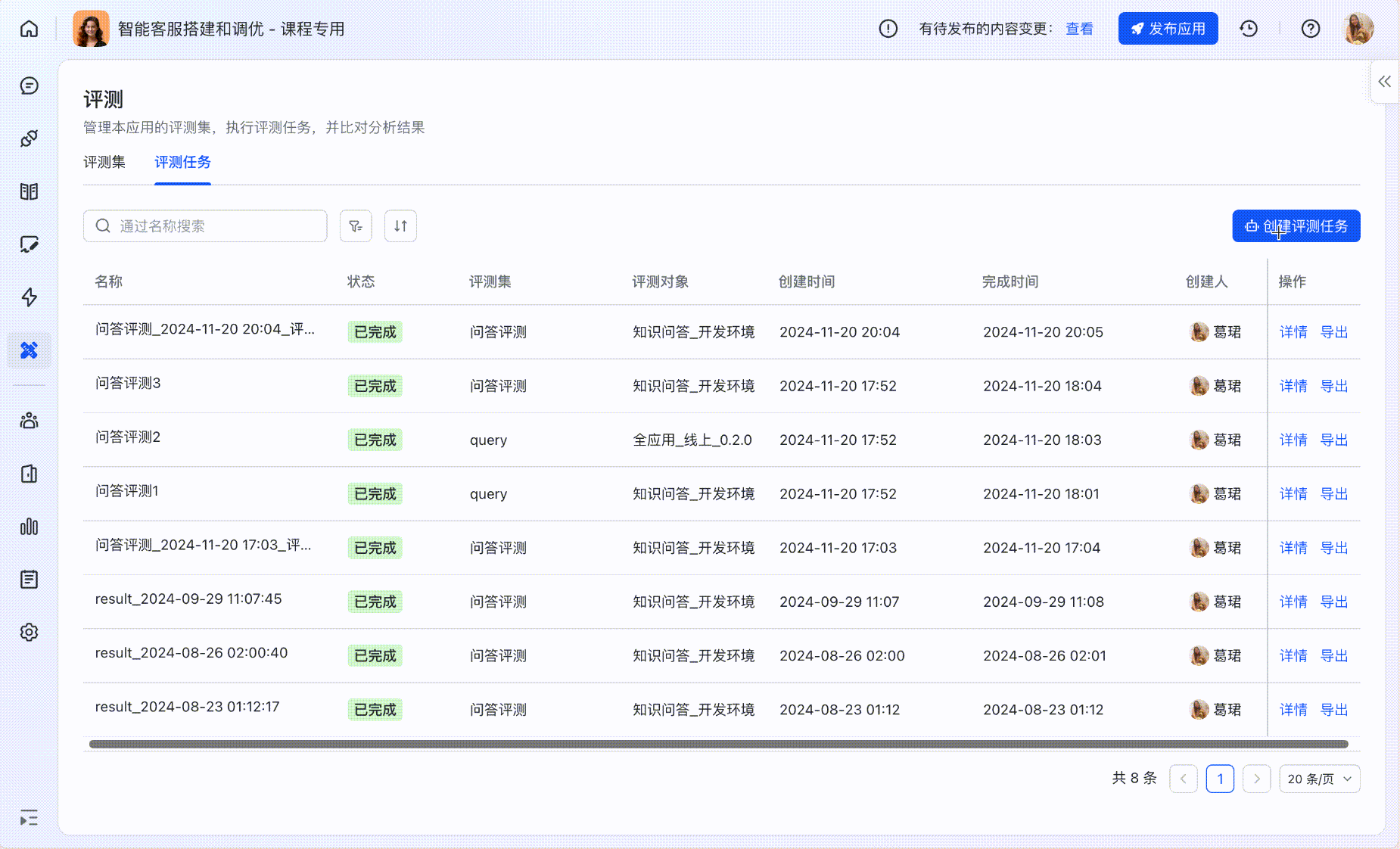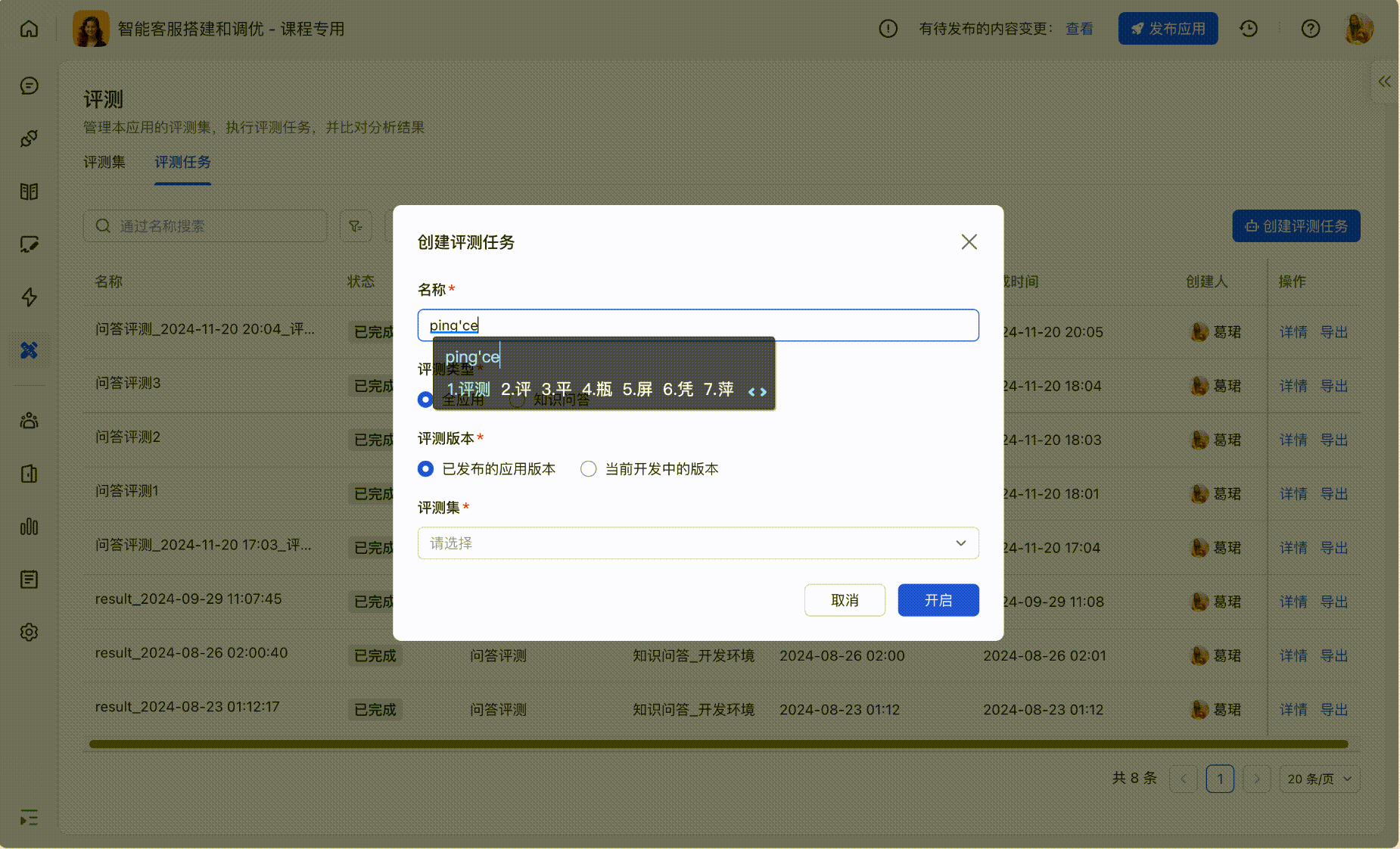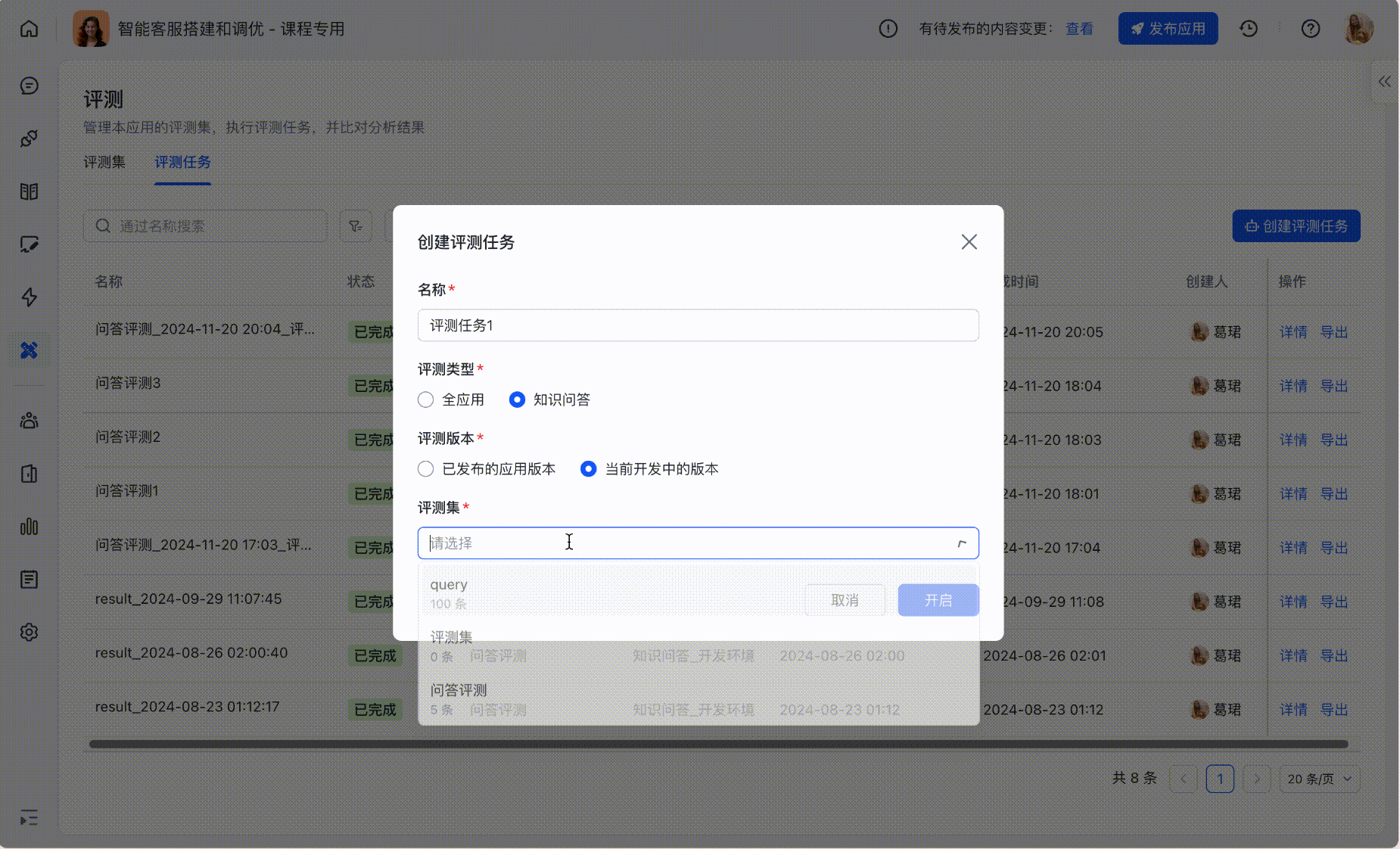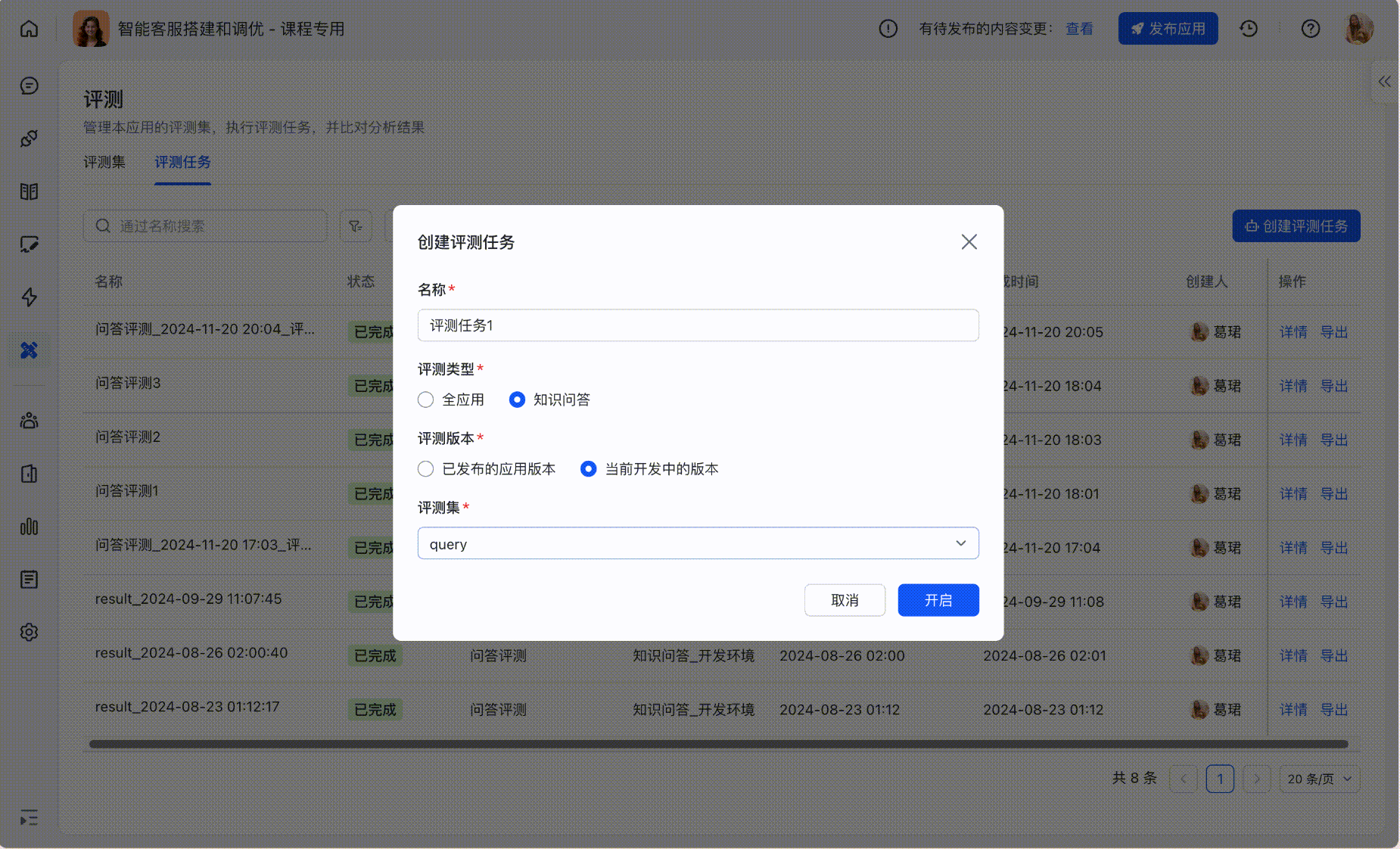
250px|700px|reset
评测权限:使用评测模块的用户需要在应用可见范围中。
- 在侧边栏「用户与渠道」模块下选择「用户管理」,在「可用范围」分栏下将需要操作评测的用户账号添加至「应用可见范围」中。
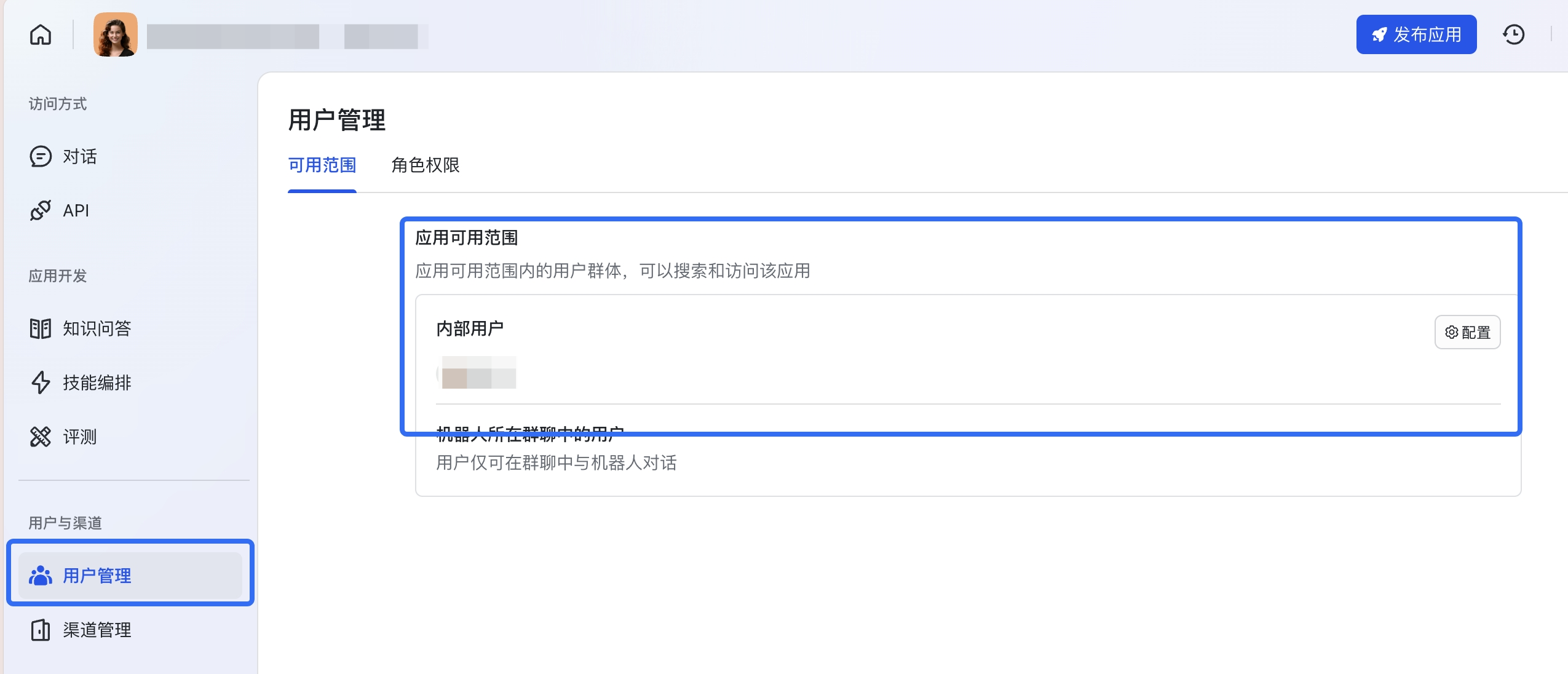
250px|700px|reset
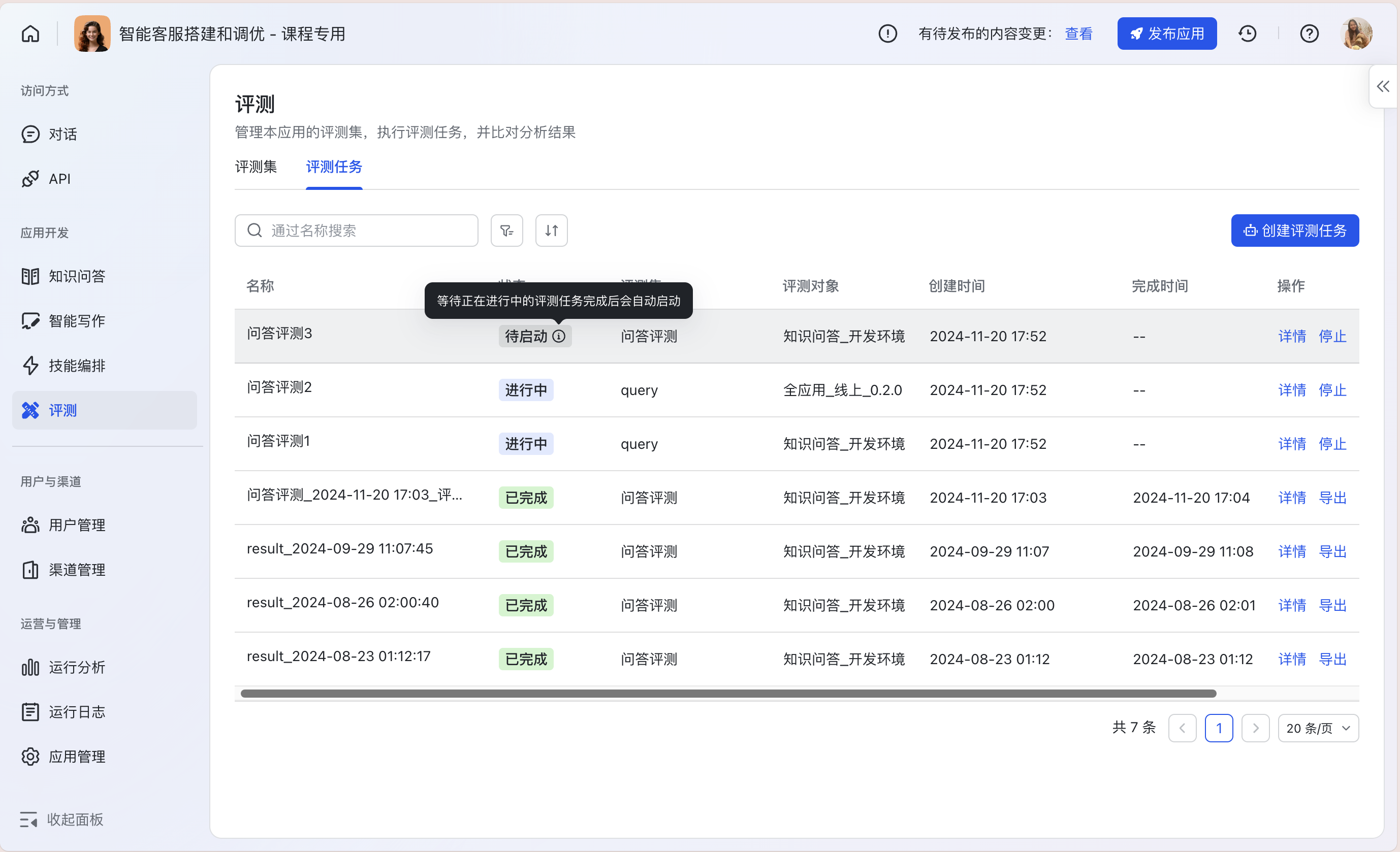
Step3:评测任务状态管理
在评测任务列表中,可同时启动最多5个配置不相同的评测任务,任务将进入队列依次自动运行完成。
- 用户可以随时停止「进行中」和「待启动」的评测任务,或查看评测任务运行详情。
250px|700px|reset
Step4:评测任务详情和人工评估
评测详情列表
在评测任务详情中,可以查看每个评测用例具体的运行情况。
- 针对「知识问答」类应用的常见行为,例如是否拒答、是否命中常用问答对等,可进行表格筛选。
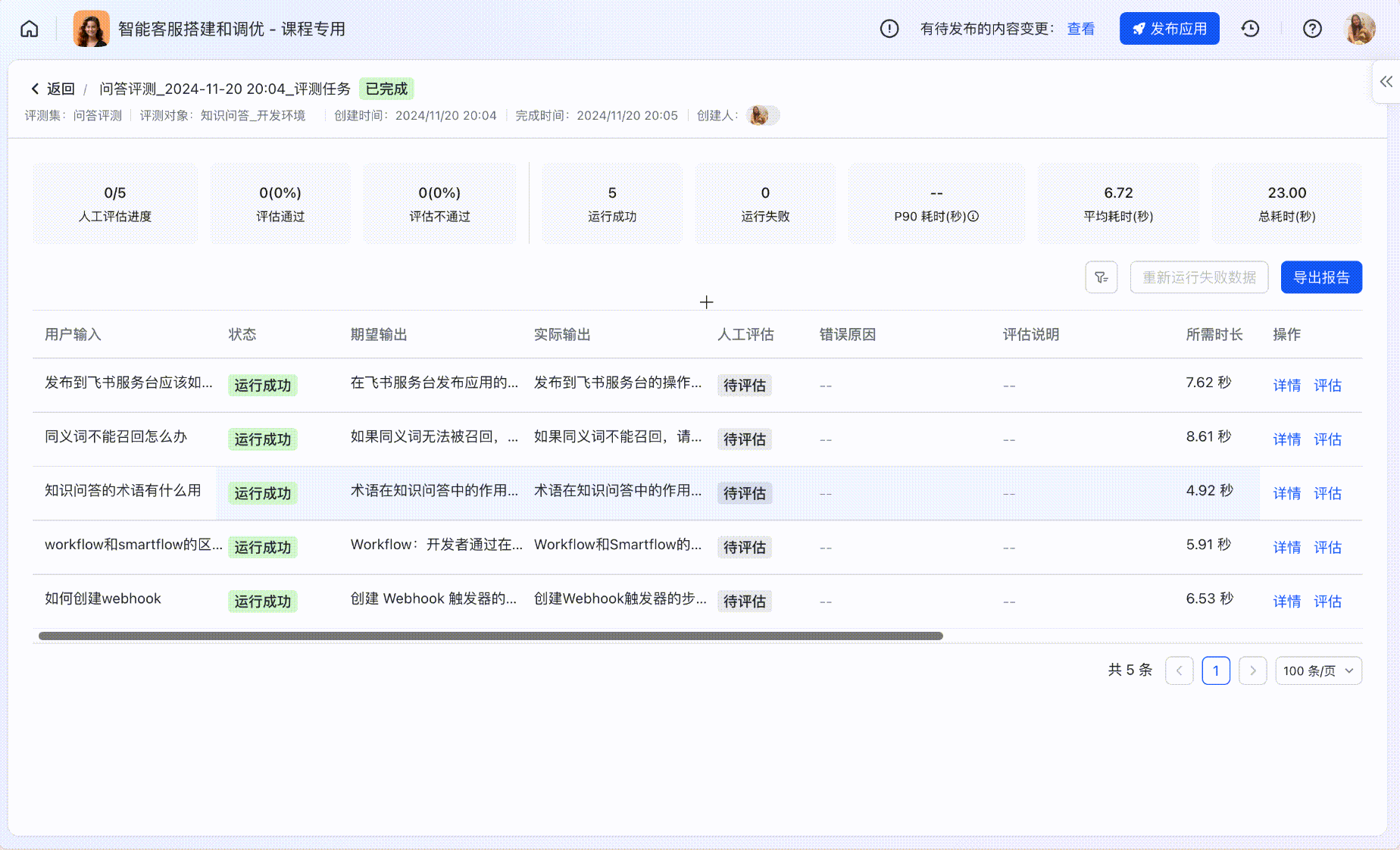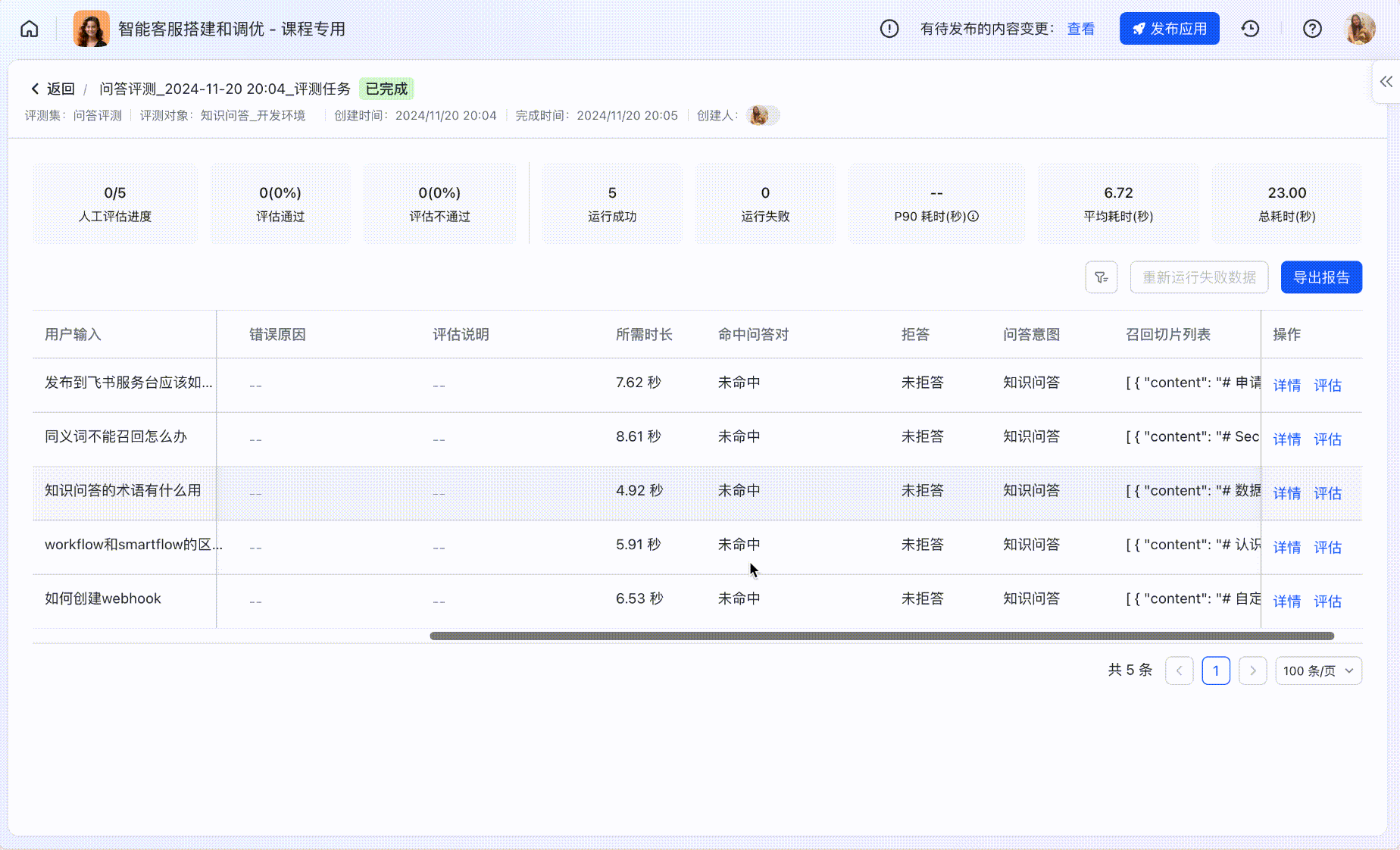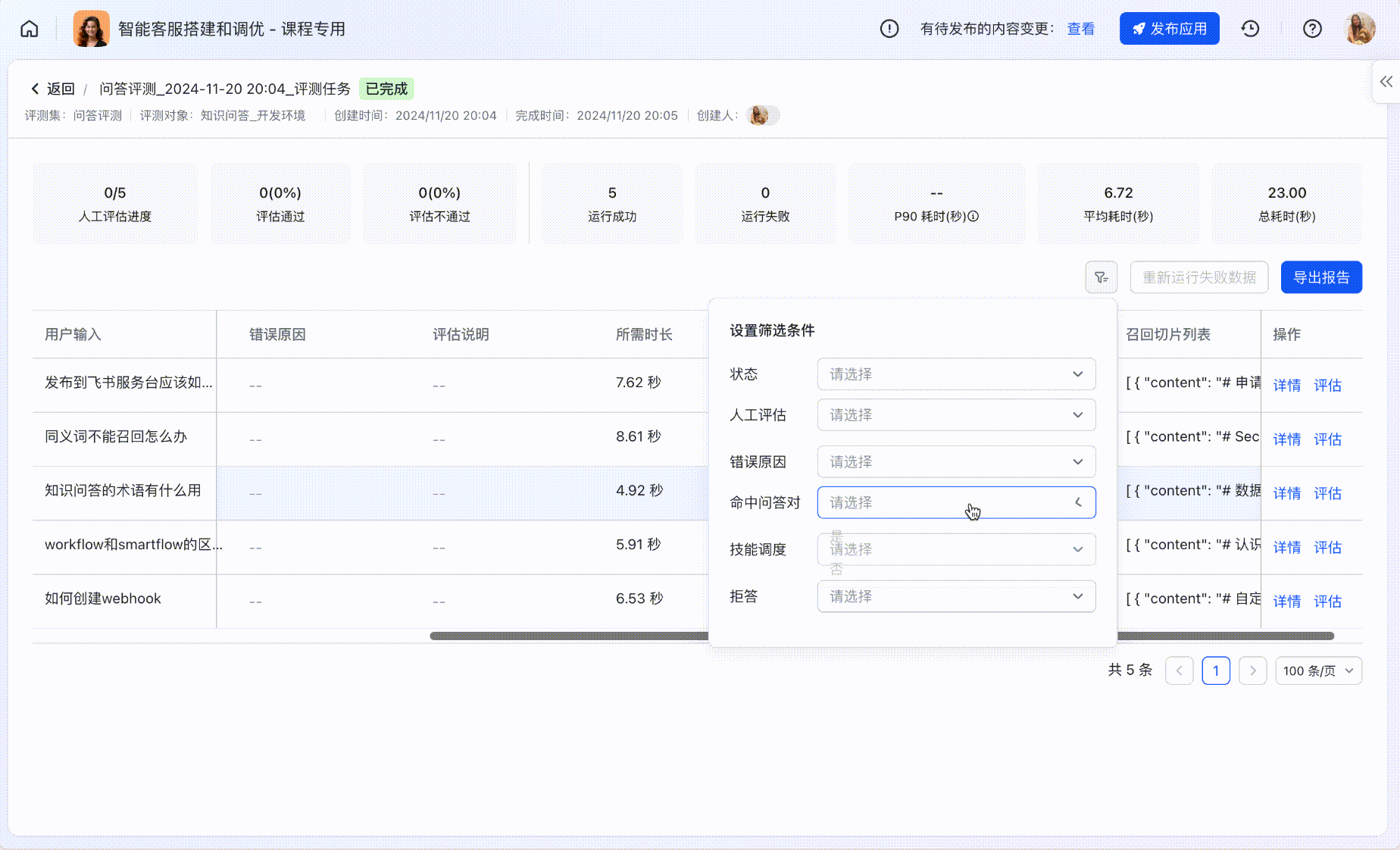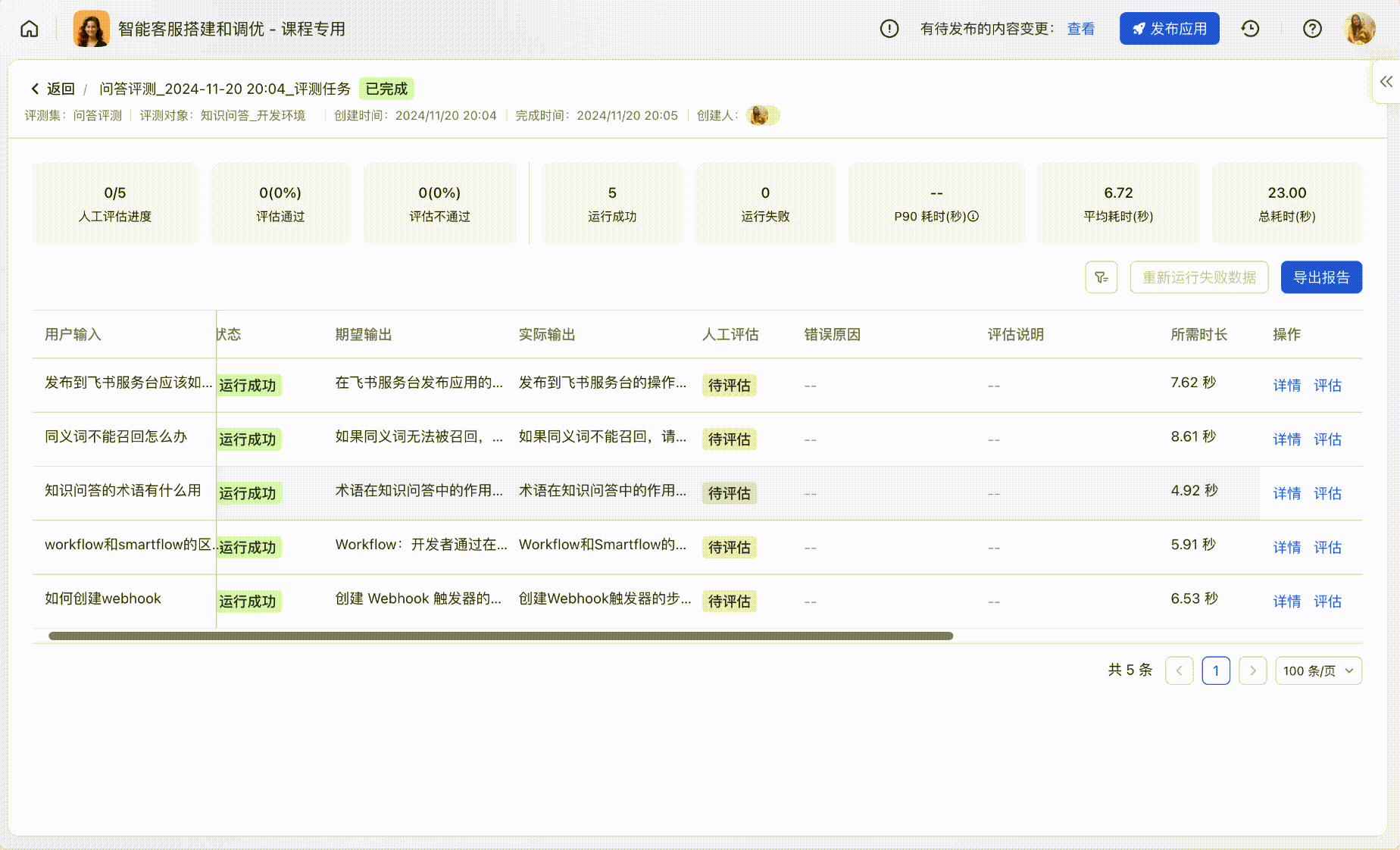
250px|700px|reset
人工评估
使用「评估」功能,对比实际运行的结果和期望输出,对评测结果进行线上打分;顶部指标卡会自动根据评估结果更新。
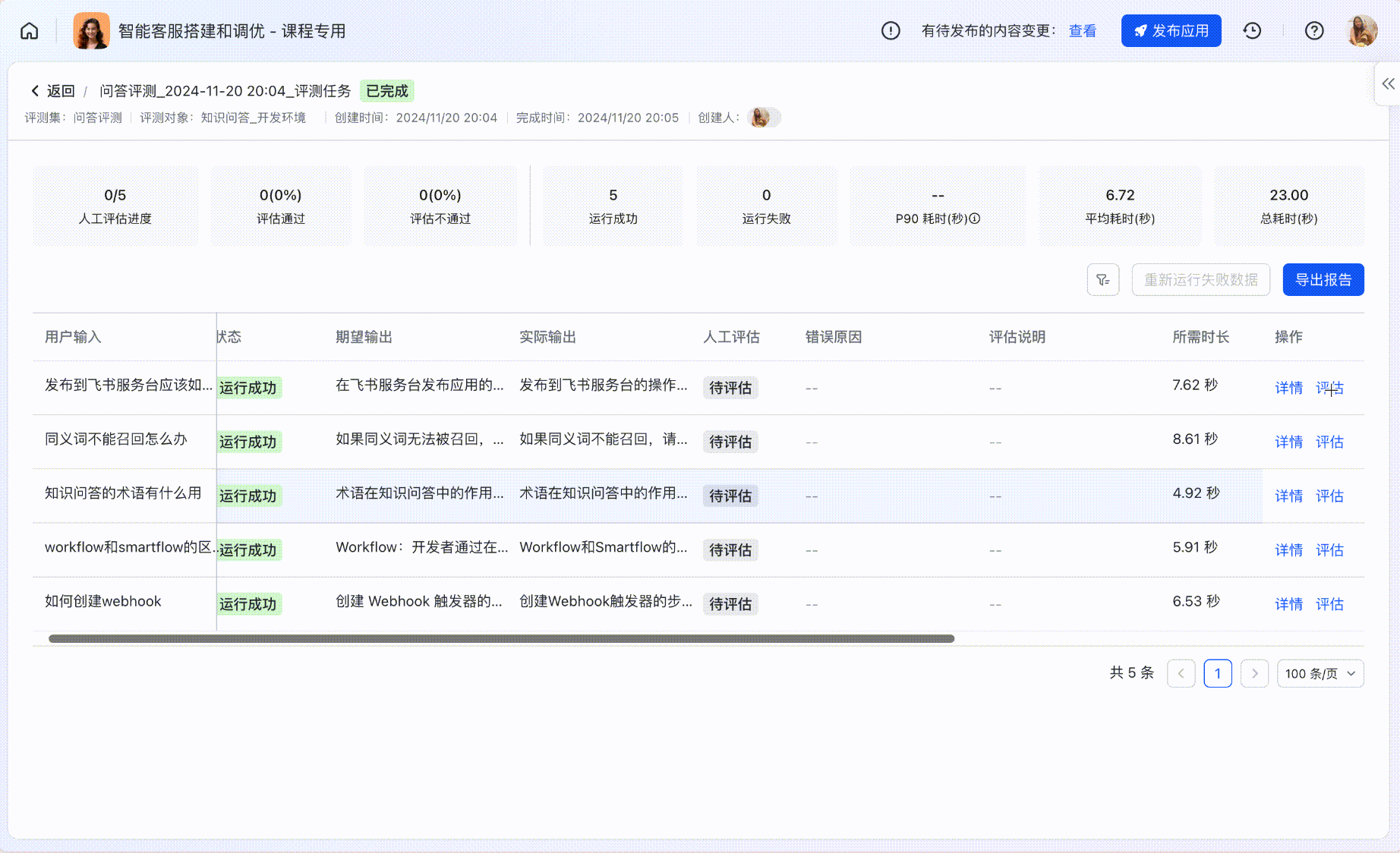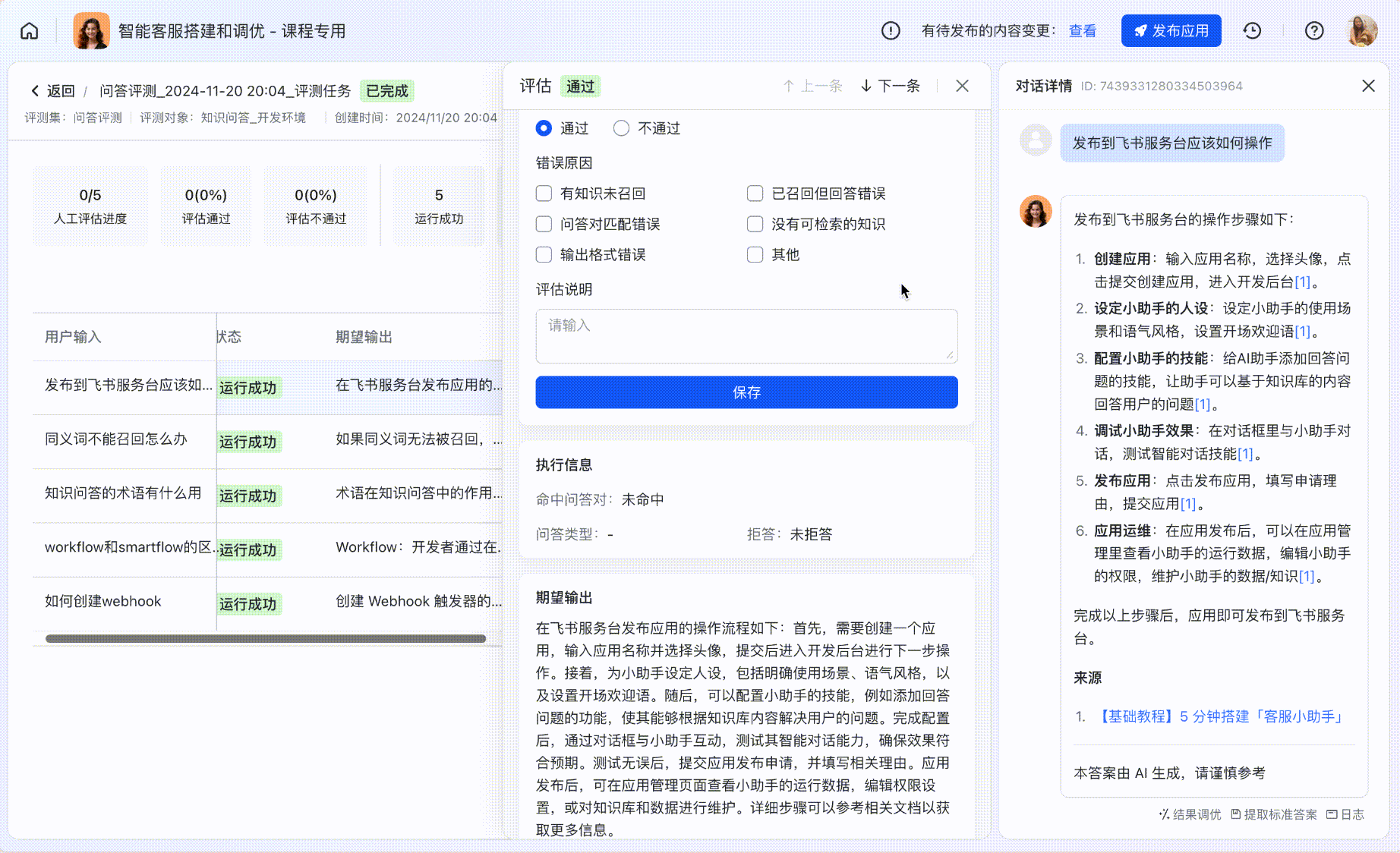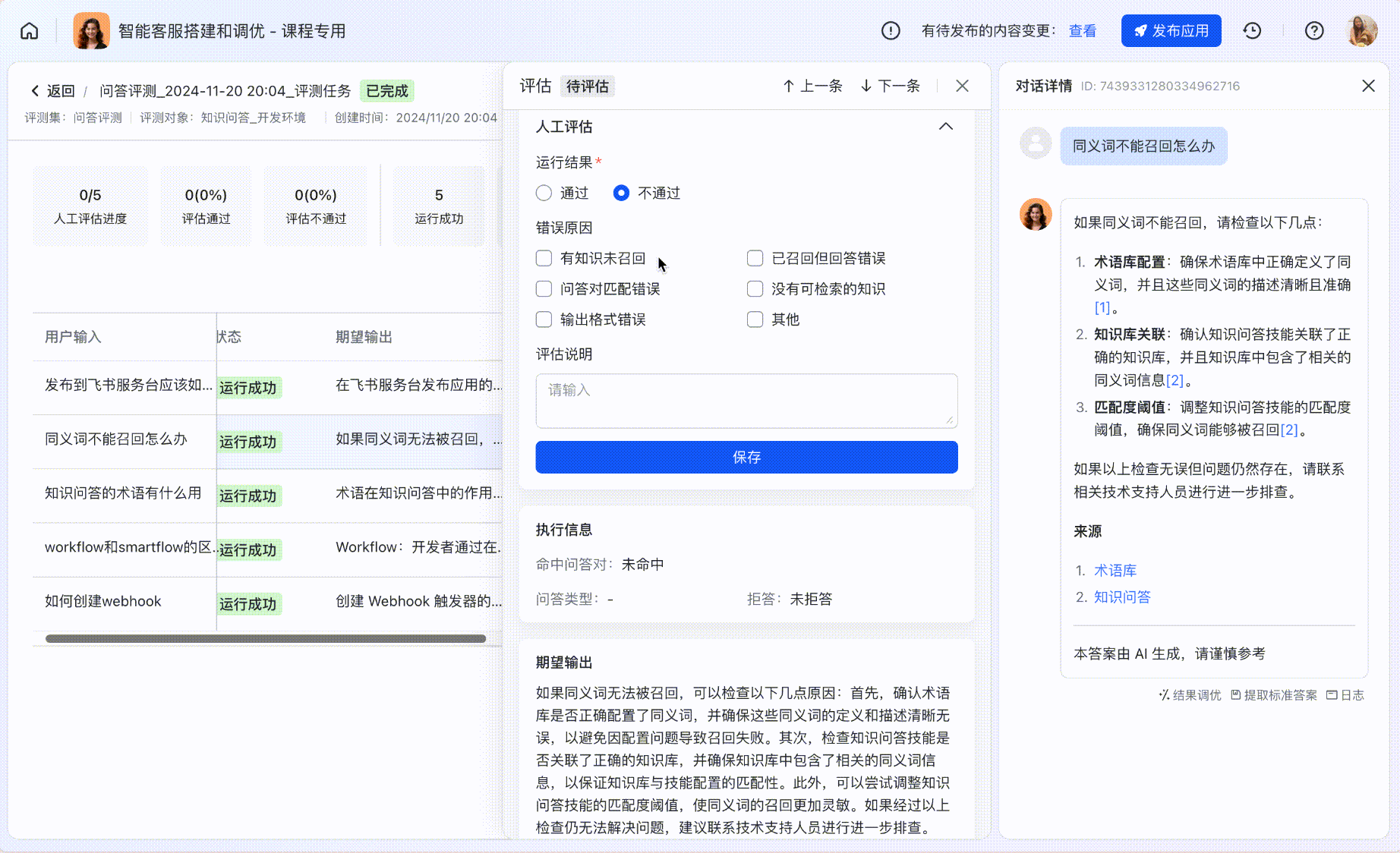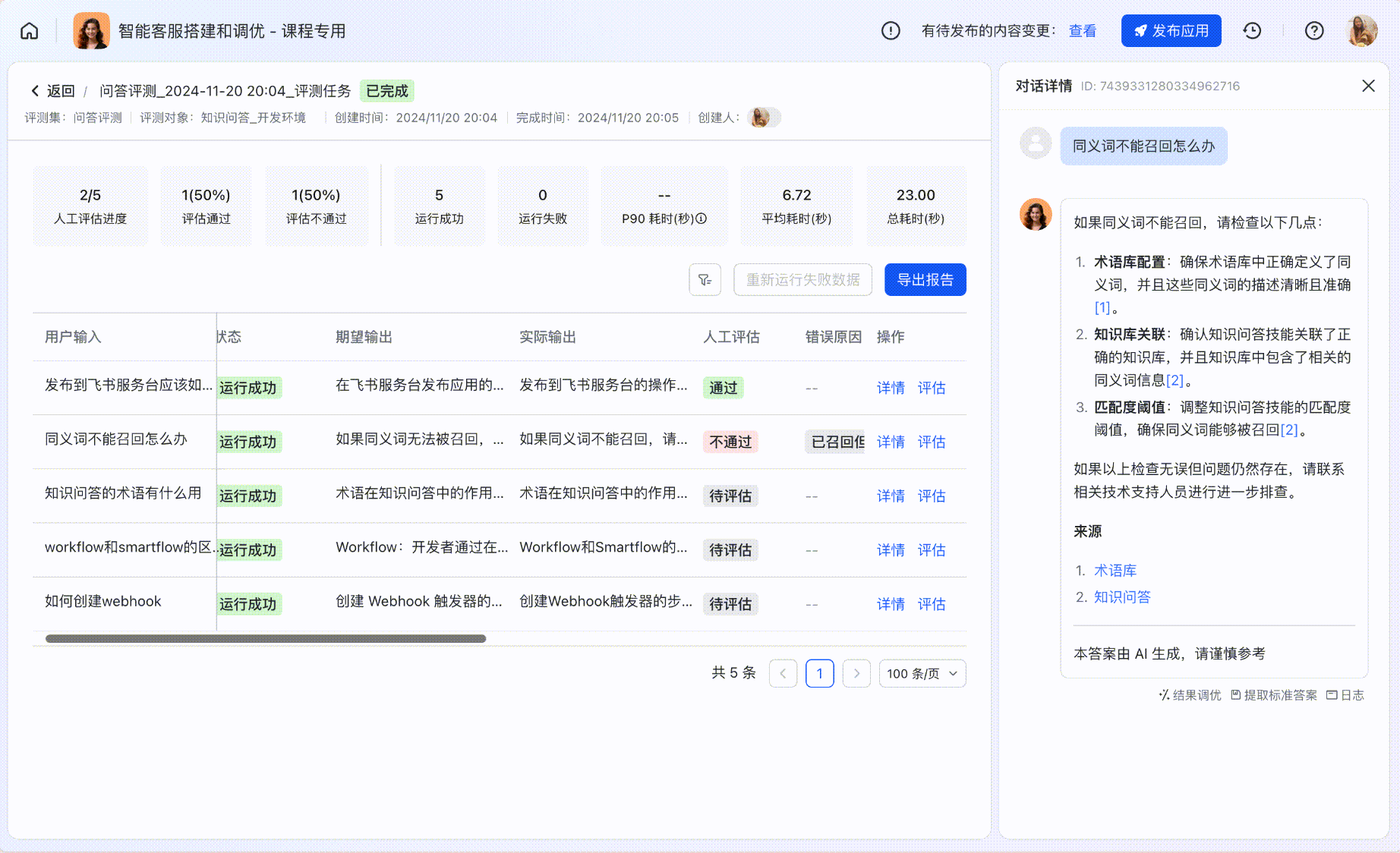
250px|700px|reset
Step5:即时调优
对于「知识问答」和「混合调度」模式的应用,可直接通过对话详情唤起知识问答调优台;针对评估不通过的用例,可以直接在评测模块中发起调优,极大提升评测之后对badcase调优的便利性。
250px|700px|reset
[评测] 常见Q&A
如何明确评测范围?
批量评测能够帮助开发者通过模拟线上用户真实使用情况,批量发现潜在的应用使用问题。从这个角度出发,可以在评测范围圈定时,选择对于业务应用上最有价值、最具代表性的待评测数据类型;是否有价值的判断可以参考以下几个维度:
- 普适性:指用户高频发生的对话类型,具有代表意义;
- 完整性:指能够贯穿应用全局使用效果测试的问题,真实分布符合业务场景;
- 高危性:指若发生了错误回答会对业务带来高危风险的问题,需要拦截拒答或者采样固定兜底话术。
如何准备评测数据?
评测数据可以基于多个来源进行准备,目前已知的来源和价值排序如下:
- 线上用户真实产生的数据:数据真实性高、分布合理;
- 业务冷启动人工造的数据:有业务经验,具有一定代表性;
- 使用AI或者策略批量构造:依赖规则的有效性,构造数据的真实性、分布情况。
评测管理会支持全应用模式、知识问答模式,评测数据准备时,用户可以根据业务需要灵活准备评测数据。
什么情况下启动评测最佳?
一句话来说,开发态调试环境下如果已经没法再发现新的badcase,可以启动评测来发现问题。评测过程会批量消耗token,建议在评测之前,先通过产品功能&调试能力,把较为明显的badcase提前解决。可单元化提效的模块,例如:
- 通过高质量的prompt模板,让知识问答能力从0-->1,参考:Aily 问答场景 Prompt 实践手册(可对外)
- 通过高质量的FAQ库输入,让FAQ问答能力从0-->1,参考:如何搭建高质量标准问答库(即FAQ)
基于评测日志,可以有哪些分析&行动?
基于评测日志,可以进行离线标注、分析和调优。
- 离线标注:根据业务对分析报告和调优的诉求,倒推标注所需的字段类型,人工打标;
- 分析:基于标注结果产出分析报告,计算准确率、召回率等指标;同时,也可以分析badcase原因和调优方式;
- 调优:当前平台支持已经支持调优方式及离线可调优的方式如下:
- 平台已支持知识问答场景优化:添加FAQ、添加术语、添加用例、修改prompt;
- 平台暂不支持但可离线完成的优化:知识源治理,面向AI可理解的模式进行治理。









