

在知识问答前置流程中,需要增强数据预处理的能力,以便为问答效果提供更高质量的数据,从而辅助提升 AI 知识问答效果。数据预处理包括文档类非结构化数据的预处理和结构化数据的预处理。
文档数据的数据预处理
接入文档数据主要用于智能问答,智能问答的整体链路大致如下:

250px|700px|reset
可以分成离线和在线的两部分:
- 离线链路:对文档数据进行预处理,建立索引。主要包括
- 文档内容提取:读取文档内容,包括文本、段落标题结构、表格、图片、链接等内容。
- 建立索引:文档内容可能会很长,需要按照文档内容结构来将文档切成许多小切片,每个切片来建立索引。需要尽可能地确保每个切片的内容语义完整,以便提高切片检索到的可能性。下面会介绍相关的切片规则。
- 在线链路:接收用户问题,从索引库中检索召回与用户问题相关性比较高的切片,并给到 LLM 来生成问题的答案。
- 检索:从离线构建的文档索引库中找到与用户问题相关的切片,会计算切片与用户问题的相似度(产品上叫匹配度),返回匹配度符合阈值条件的切片。
- 生成:将用户问题、检索到知识切片一起组成上下文信息,让 LLM 来生成问题的答案。
文档数据的预处理主要介绍离线链路的文档内容提取和索引建立。
文档内容提取
注:下面表格中的“自动同步?”主要标识文档数据源有内容变更,是否会自动同步最新的文档内容。
表数据的扩展学习:
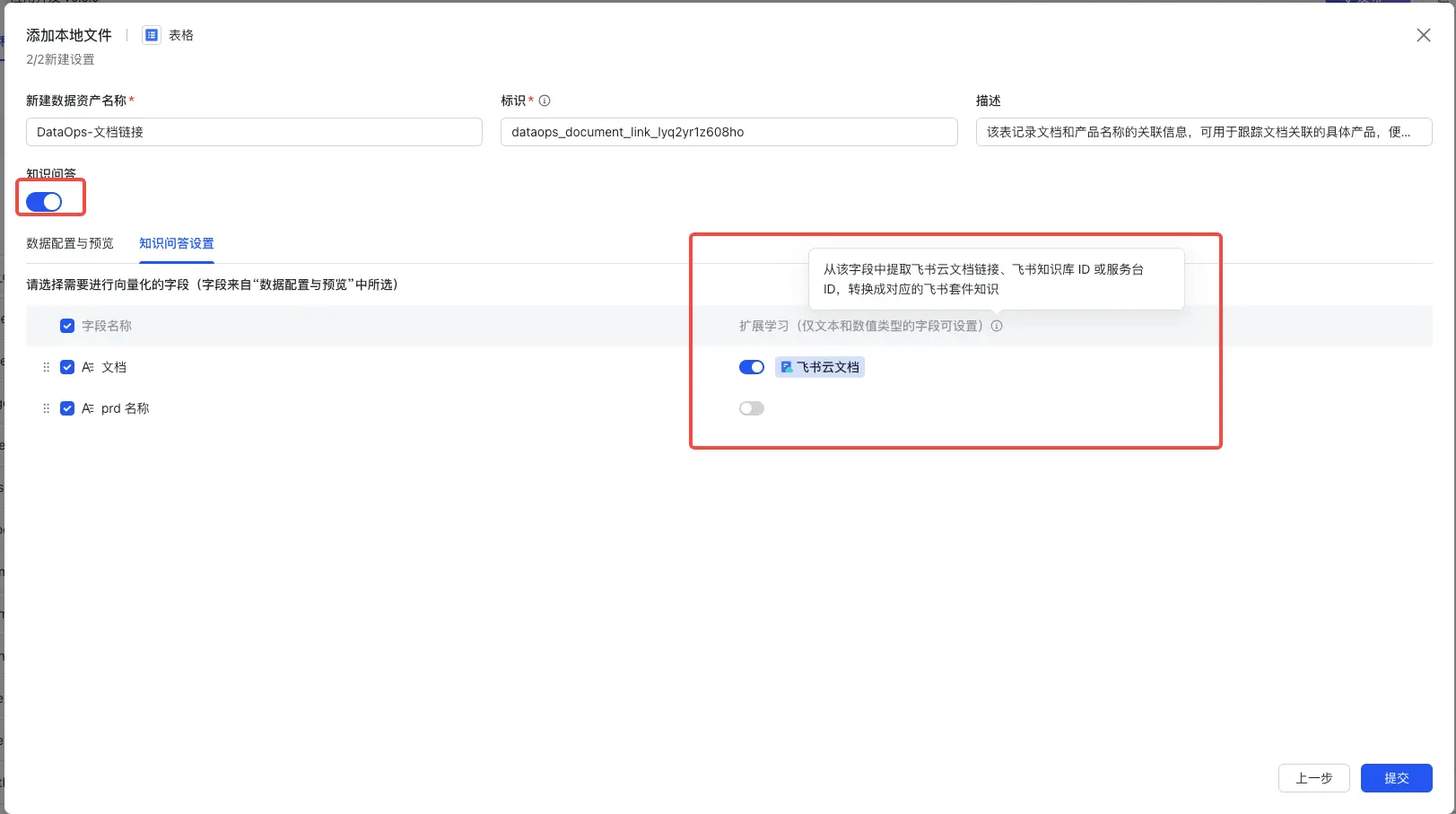
在添加结构化数据时,若开启了知识问答,选择提取哪些字段的内容来作为非结构化数据,用于知识问答。
针对所勾选的字段,可选择是否要开启”扩展学习“。
- 文本类型字段:判断该字段内容是否包含合法的飞书云文档链接。若包含,则提取该文档链接,并将对应的飞书云文档作为该数据资产的扩展知识列表。在知识问答时,也会从这些扩展知识列表中检索相关的知识。
- 数字类型字段:判断该字段的值是否是一个合法的飞书知识库 ID 或服务台 ID。若是,则自动将对应的飞书知识库或服务台作为该数据资产的扩展知识列表。在知识问答时,也会从这些扩展知识列表中检索相关的知识。
250px|700px|reset
建立索引
切片规则
默认切片规则
知识源类型 | 默认切片规则 |
本地文件 |
|
飞书云文档 | 每篇文档,我们会将其拆分成多个片段,每个片段由三个部分拼接而成:
每个片段拼接后的长度不能超过 512 个字符。 250px|700px|reset |
飞书服务台 | 每个问答对一个切片。 |
结构化的表数据 |
|
自定义切片
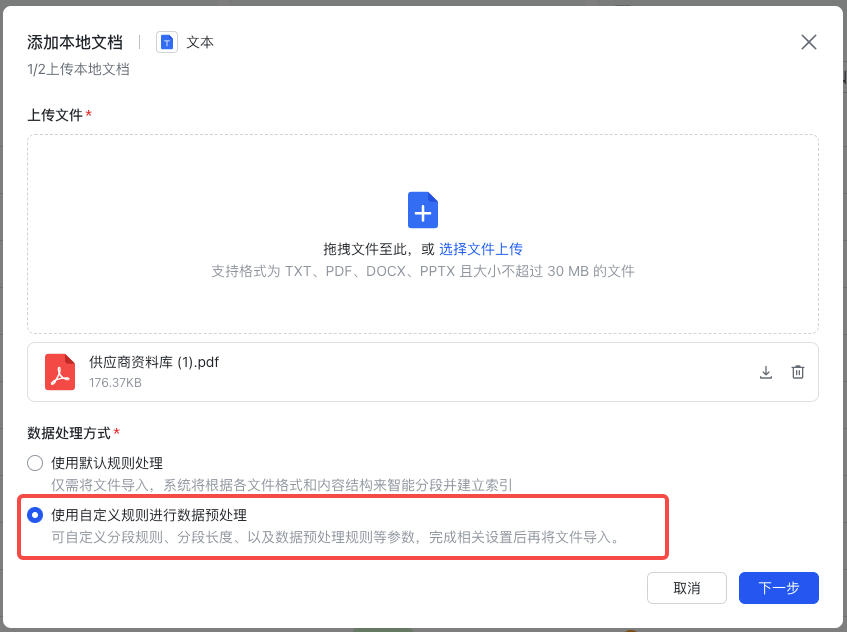
针对本地文件,支持用户选择采用自定义切片规则来对文档内容进行切片。
- 添加本地文件时,选择“使用自定义规则进行数据预处理”
250px|700px|reset
- 下一步,设置自定义切片规则
- 分段标识符:目前支持两种自定义切片规则。
- 段落分隔符:会按照顺序依次采用 /n/n、/n、空格 分隔符进行分段,确保每个切片的长度不超过所设置的分段最大长度。
- 特定分隔符:目前只支持了固定的 ###### 分隔符。
- 分段最大长度(字符):200 到 1000
- 分段重叠比:
- 若按照分段标识符切出来的某个切片长度超过所设置的最大长度,则会按照最大长度进一步切成小切片。
- 为了尽可能保障小切片的语义完整性,在这些小切片的前后会与前后的小切片有一定比例的内容是相同的。

250px|700px|reset
修改切片内容
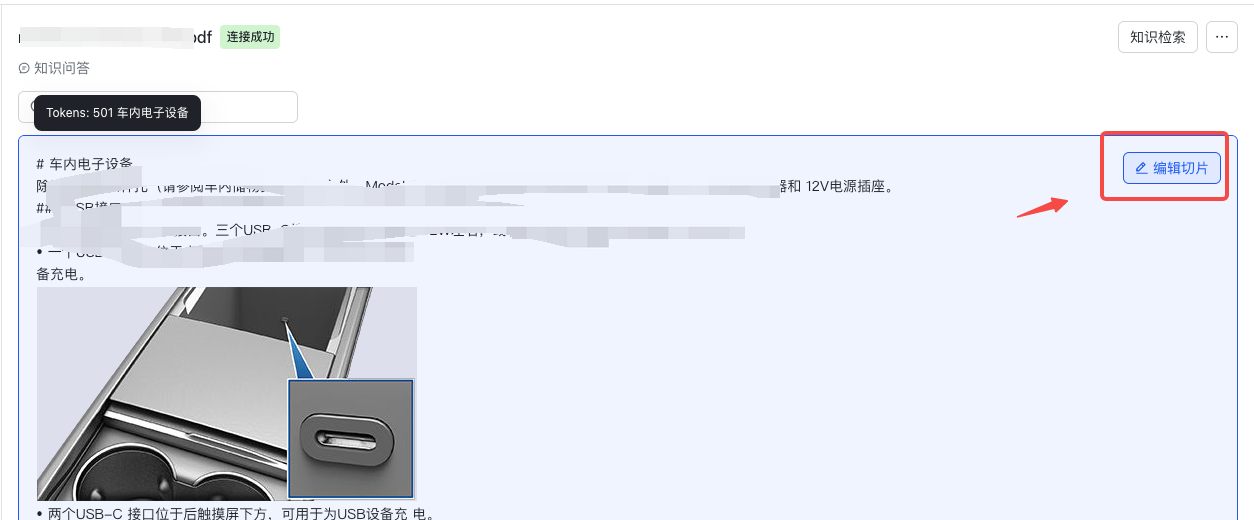
针对本地上传的文件,支持修改单个切片的内容,修改切片内容时支持插入图片。
- 在数据资产详情页面,Hover 到某个切片时,会提供「编辑切片」按钮。
250px|700px|reset
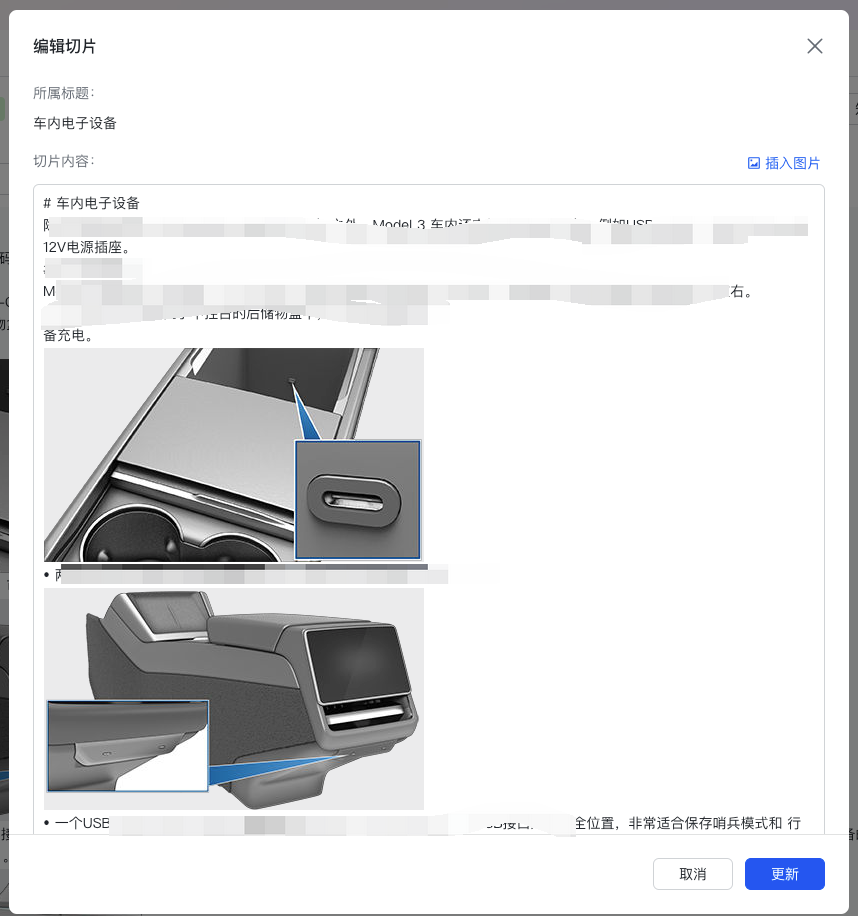
- 在切片编辑页面,可以修改切片内容,也可以选择本地图片插入切片。
250px|700px|reset
结构化数据的数据预处理
AI生成字段
功能描述
AI生成字段,又叫智能数据处理,是一种利用大模型对数据进行标记、注释、信息提取或者总结的过程,数据内容生成于新的数据字段中,因此又称为AI生成字段。
AI生成字段的原理为基于大模型的信息提取和归纳、分类等能力,实现对批量数据的智能处理。它可以提高数据处理的效率,减少人工处理的成本和时间。
应用场景
智能标注
- 场景描述:利用模型的识别能力,根据数据的特征和语义,自动地对数据进行分类、标记或注释,以便后续的处理和分析。智能打标或标注可以用于文本分类、情感分析、舆情分析等任务。
- 场景示例:
- 在文本分类任务中,模型可以根据文本的内容和语义,自动地将文本标记为不同的类别,如:新闻、小说、论文、邮件等。
- 在情感分析任务中,模型可以根据文本的内容和语义,自动地将文本标记为不同的情感类型,如:正向、负向、中性等。
信息提取
- 场景描述:信息提取,即模型提取字段,从文本数据中提取出特定的字段或特征,以便进行进一步的数据分析或处理。
- 场景示例:
- 在实体识别或字段提取任务中,模型可以根据文本的内容和语义,自动地识别出文本中的实体或字段信息,如人名、地名、组织机构名、客户名称、邮箱、地址、时间等。
-
文本总结
- 场景描述:让模型根据给定的文本生成一个简洁、准确、完整的摘要或者从长段的文本数据中提炼出关键信息。
- 场景示例:
- 在文本总结任务中,对一段客户需求反馈或者会议纪要等长文本,进行信息总结,提炼出关键信息。
- 在文档摘要任务中,对一篇新闻或者文档类的内容自动生成摘要,帮助快速了解主要内容或者提取出关键信息。
操作说明
AI生成字段的功能入口
数据资源详细页->数据视图->AI生成字段
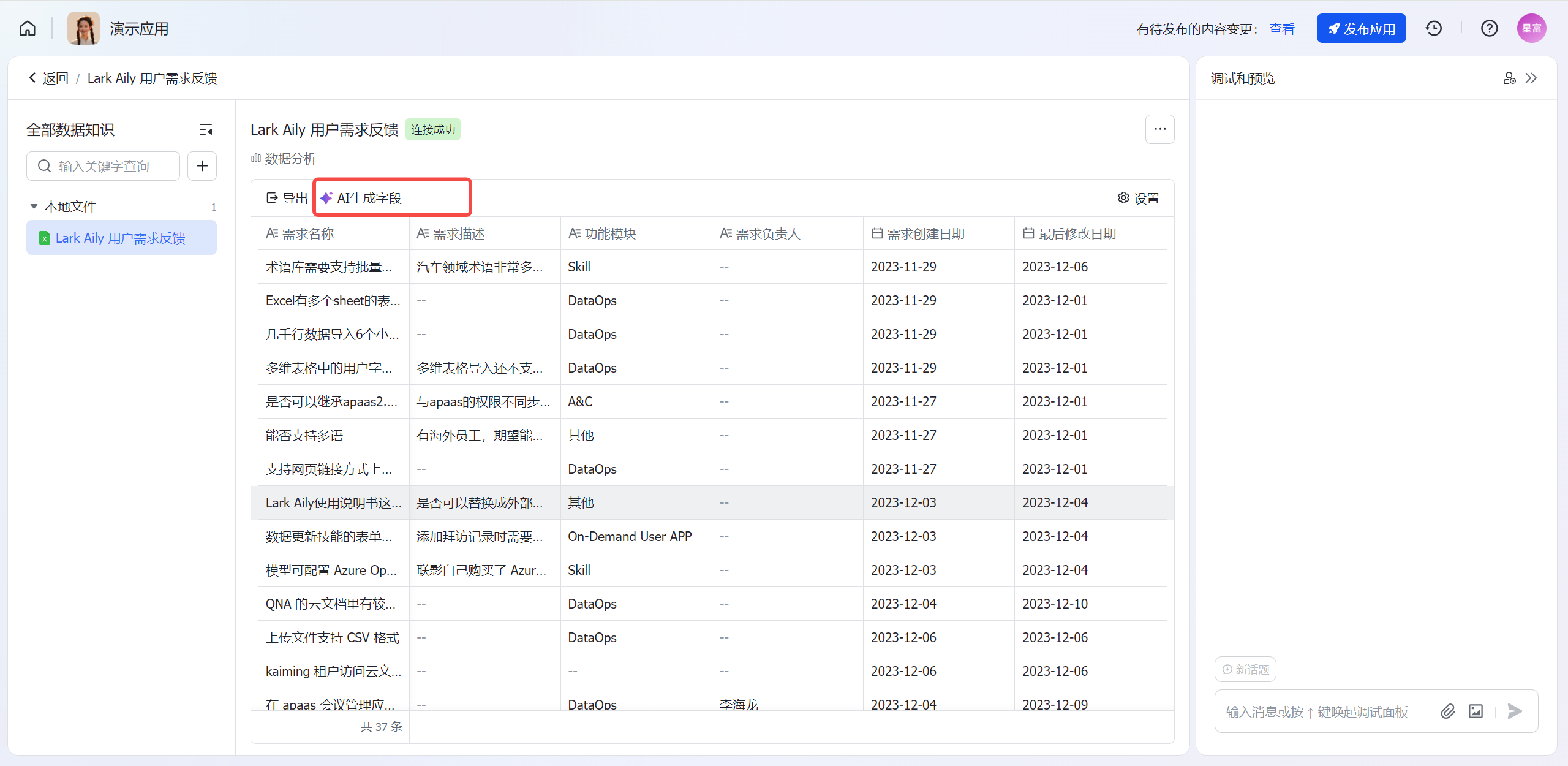
250px|700px|reset
新增AI生成字段
新增AI生成字段,界面示例如下:
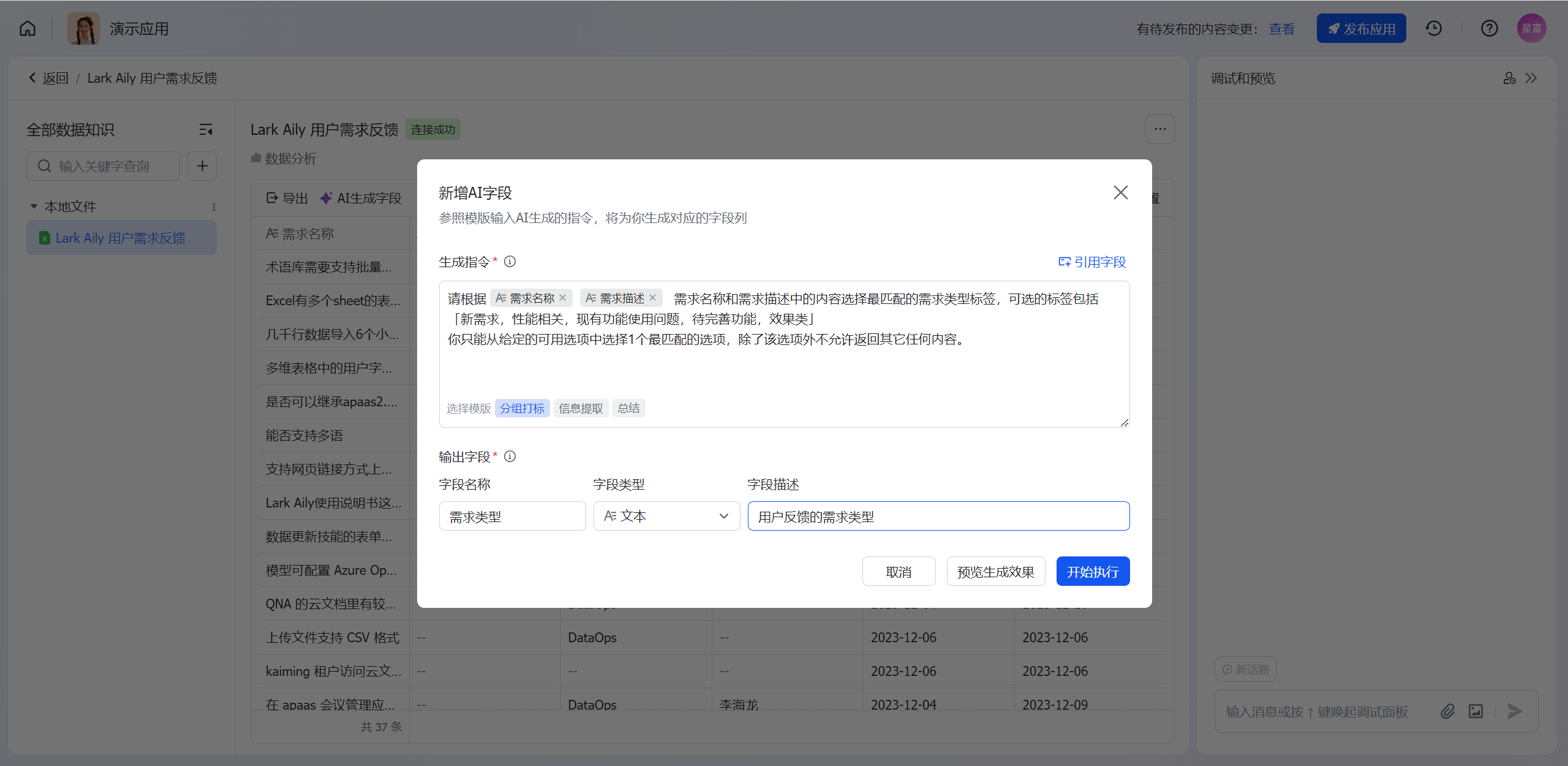
250px|700px|reset
用户需在界面中输入如下信息:
- 选择模板:
- 目前平台提供了分组打标、信息提取、总结三种生成指令的模板,用户可以基于模板进行自定义的修改。
- 平台提供了模板的生成指令样例。
- 生成指令:
- 生成指令为提供给大模型的prompt输入,输入的生成指令中包含所引用的数据字段,对输出数据的定义、描述,输出格式的要求。
- 生成指令要求编写尽量准确,对于数据规则的定义清晰,便于模型理解。
- 生成指令是影响生成效果和准确性的重要输入,在编写生成指令后可点击预览生成效果,进行生成指令的调试,效果调试至生成数据满意后,提交生成任务。
- 引用字段:
- 引用字段为AI生成数据的原始数据输入,模型会对每条记录(行)的数据引用指定的字段(列)生成数据。
- 可以引用1个或多个字段。
- 输出字段:
- 输出字段是模型生成数据后的新字段,平台将在对应的数据中创建输出字段并把生成的数据存储到该字段中。
- 需要指定标注的结果需要输出的字段、字段类型和描述信息,信息提取可以提取到多个字段,分组打标 与 总结均只能输出到一个字段。可以指定输出字段的类型和格式,输出的新增字段追加到现有的数据视图中。
- 字段名称:填写中文名称,要求与生成指令中的输出要求中的字段名称相一致。
- 字段类型:文本、整数、日期时间、日期、浮点数、定点数、布尔,根据生成指令中的输出格式要求选择。
- 字段描述:根据生成指令中的输出要求描述。
- 调试预览:完成AI生成字段的指令和输出字段填写后可点击预览生成效果,平台提供前5条记录的数据生成预览功能,用户可在新增窗口中预览前5条数据,确认生成指令的生效。完成预览生成后,点击开始执行,则完成AI生成字段的新增。
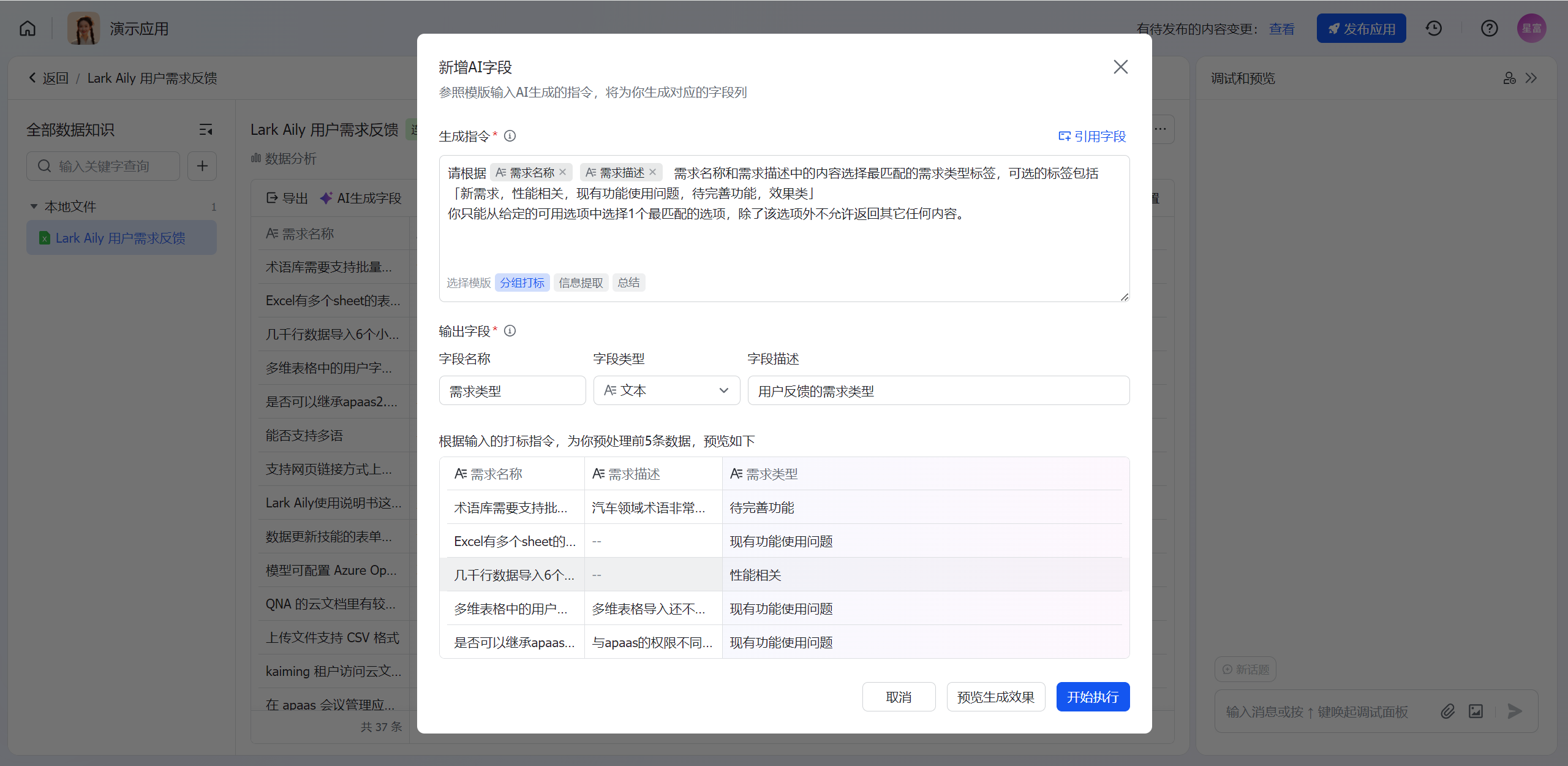
250px|700px|reset
更新生成数据
更新全部记录
用于重新编辑打标指令,或输入的原始数据发生整表更新后对全部记录重新生成一次。
在数据详情页的列表中的对应字段点击[重新生成所有记录],重新生成所有记录可对生成指令和引用字段重新编辑,但输出字段不支持编辑,如需要同时编辑生成指令和输出字段,可以先删除字段,重新新增AI生成字段。
完成指令的编辑后,可点击预览生成效果,平台提供前5条数据记录的效果预览,确认效果后点击开始执行提交更新所有数据记录。
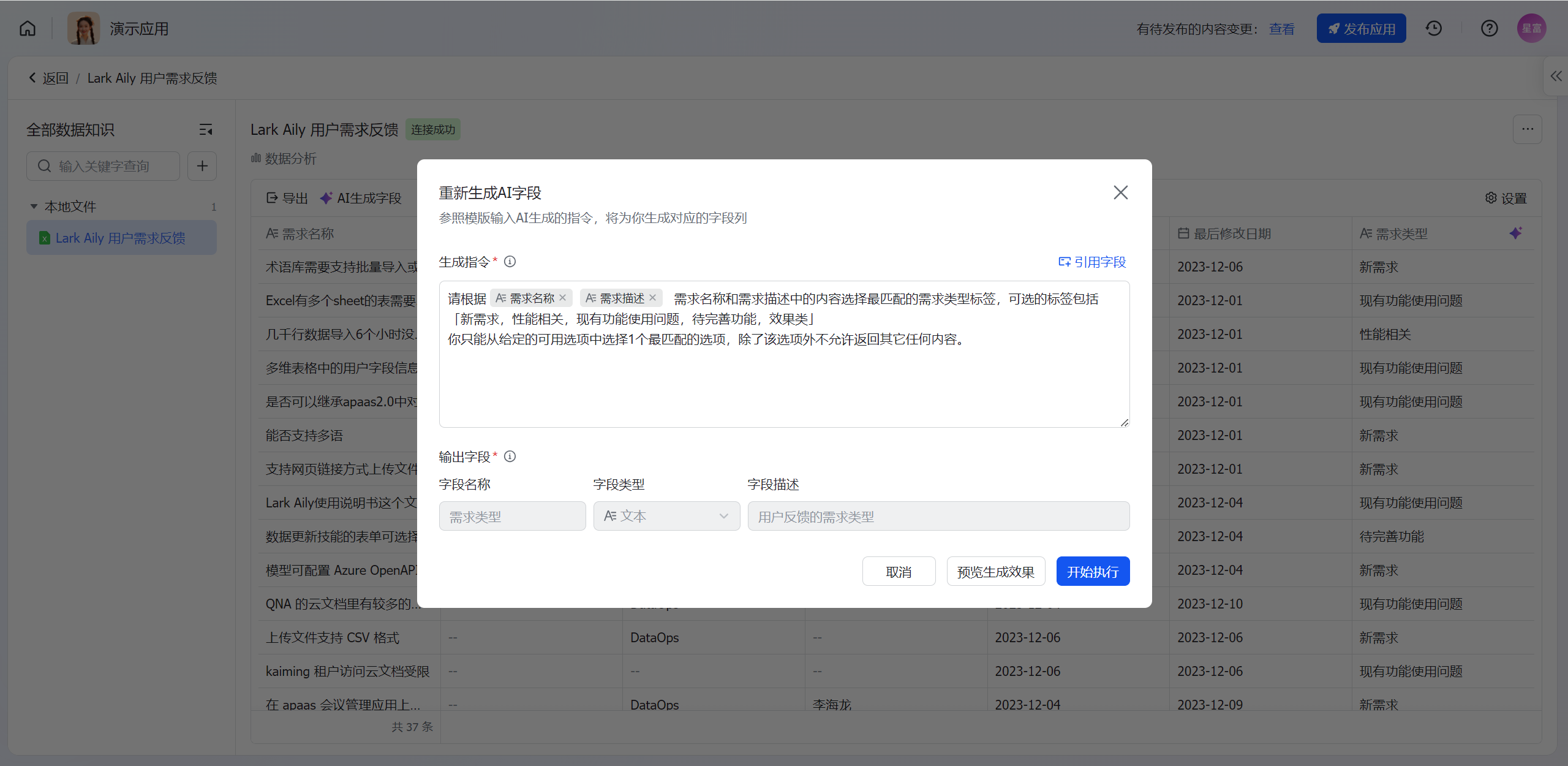
250px|700px|reset
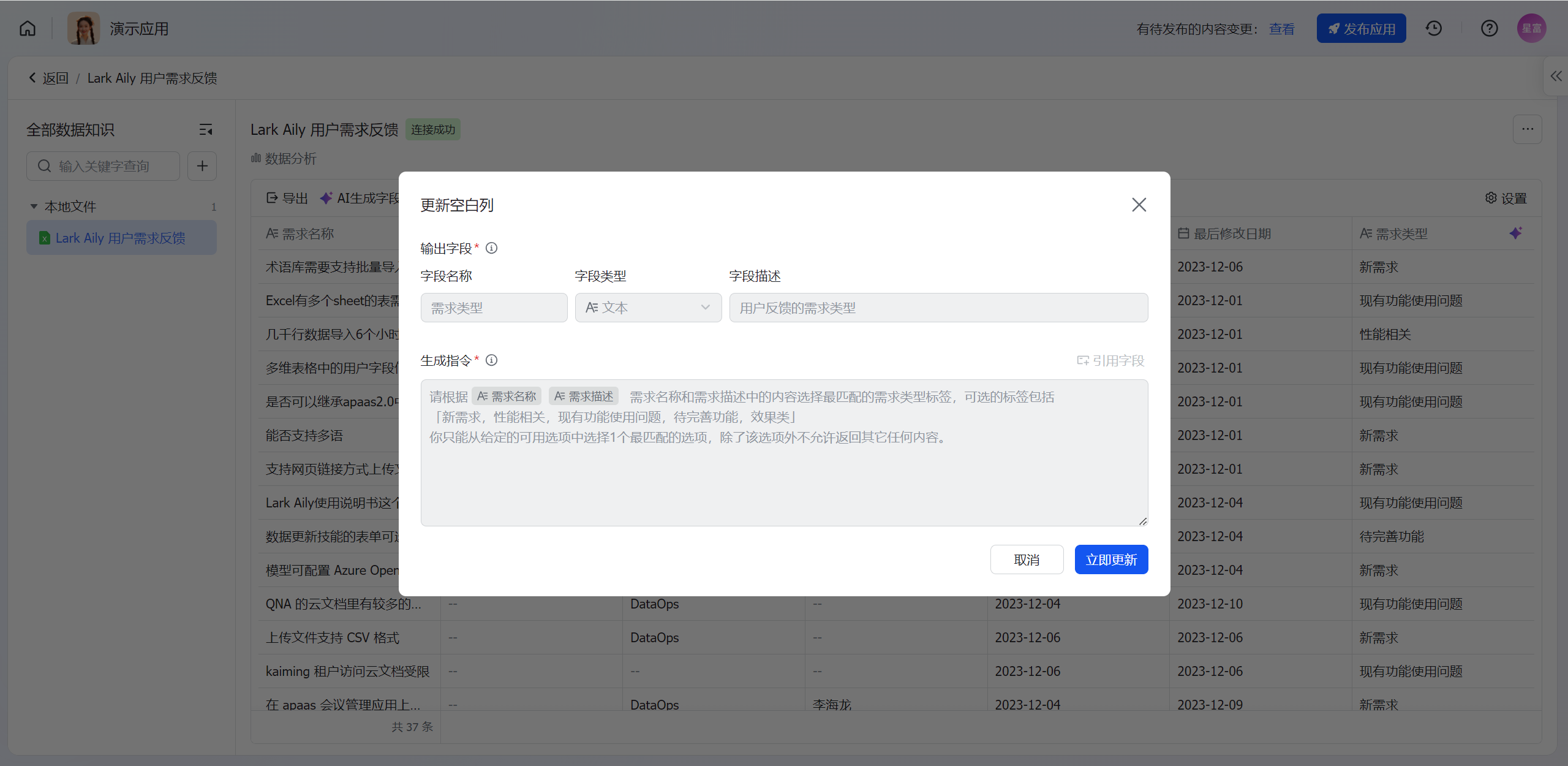
更新空白记录
主要用于对增量的数据进行更新,即新的数据进来后,运行更新空白记录对新的数据进行生成。
在数据详情页的列表中的对应字段点击[更新空白记录],更新空白记录不能修改生成指令和输出字段,提交后立即更新空白记录数据。
250px|700px|reset
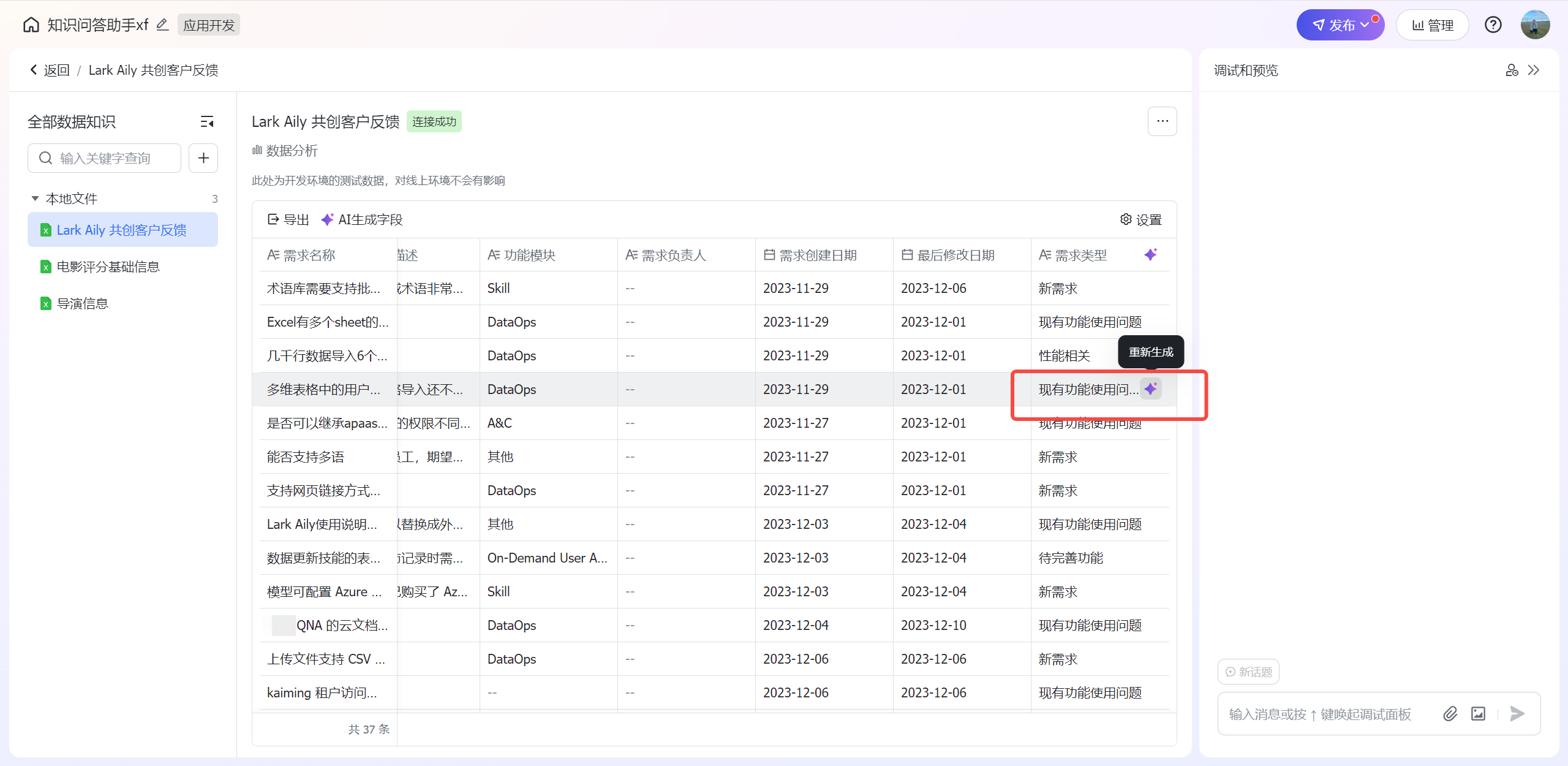
更新单条记录
用于对单条的记录数据进行生成或重新生成。
250px|700px|reset
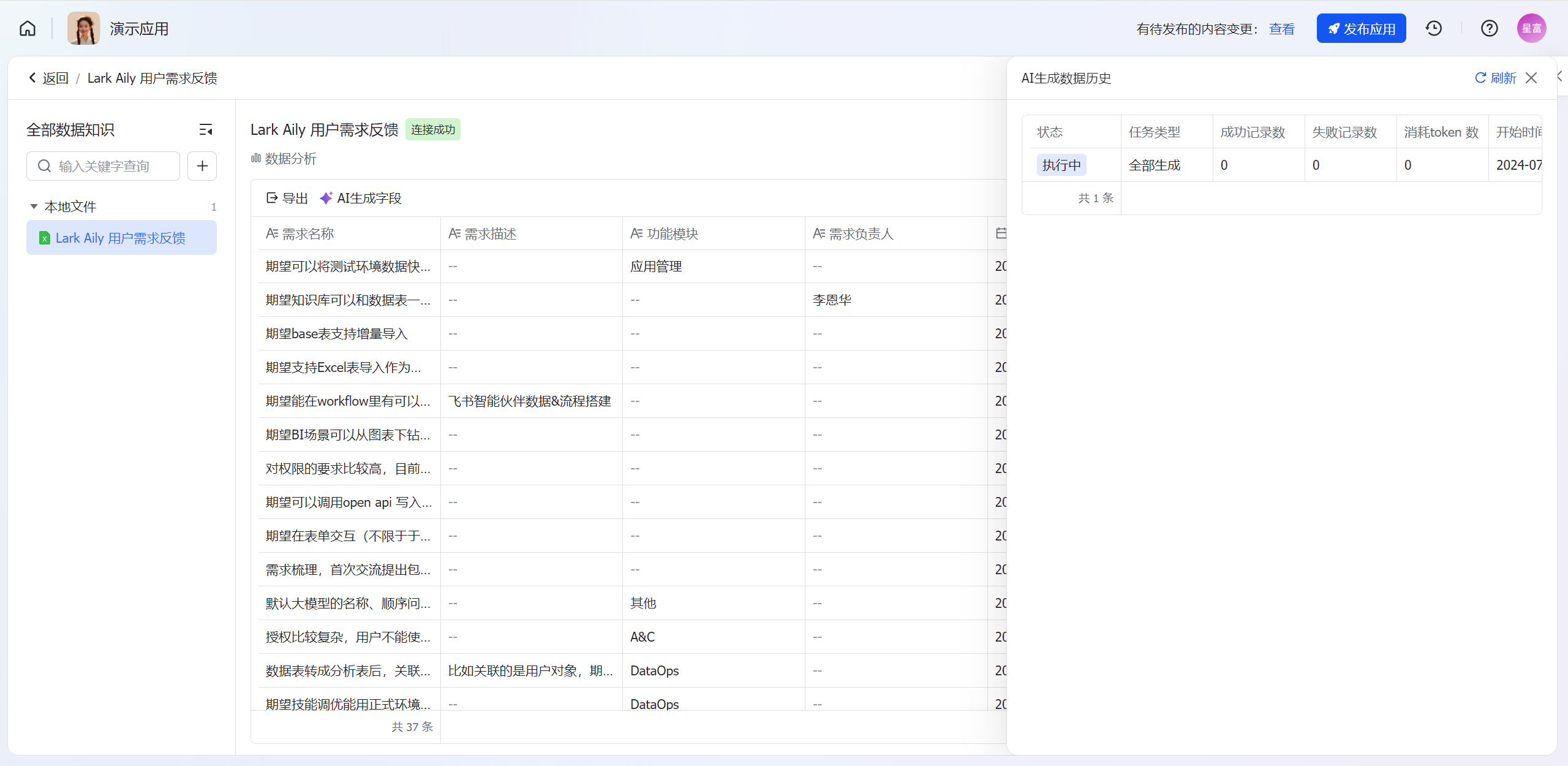
查看执行历史
针对AI生成的字段,可以在数据详情页的列表中查看AI生成的历史。生成历史包含如下信息:状态、任务类型、成功记录数、失败记录数、消耗token数、开始时间、结束时间和提交人。每提交一次更新生成数据的任务,则新增一条执行历史。
你也可以在提交生成任务等待过程中查看执行历史,以了解目前生成任务的整体进度情况:
250px|700px|reset









