

作者:王健
推荐理由
实现从风神数据集中实现数据自动加载至larksheet,并同时加载至飞书文档中;与此同时完成最近X周期的Mini图制作并输出。
一、背景
- 我是来自字节跳动-国际电商-数据科学- GNE(治理与服务体验)DS团队的@王健,如果对本文有任何疑问欢迎随时联系我!(📮wangjian.maxwell@bytedance.com)
- 在电商业务周会/双周会中一般需要将核心数据、环比、以及趋势图作为核心内容放入周报中,但由于指标较多且制作mini图较为繁琐,因此很多同学都苦于复制粘贴的工作。
- 通过本文希望能够帮助大家实现如何从风神数据集中实现数据自动加载至larksheet,并同时加载至飞书文档中;与此同时完成最近X周期的Mini图制作并输出。
二、前期准备
- 一个飞书机器人并申请相应权限
- 一个空的飞书表格以及文档
- 一个承载数据可视化查询的仪表盘
- 可打开并执行的风神notebook
- 一颗勇于探索和尝试的心
三、 建立飞书机器人
3.1 注册机器人地址
3.2 注册流程
整个申请链路如下:
1、如图一:点击首页【创建应用】
2、如图二:点击【创建企业自建应用】
3、如图三:输入自己机器人的应用名称和应用描述,点击【创建】
4、如图四:点击【凭证与基础信息】
- 记住这里的App ID和App Secret(这个是你机器人的身份信息和唯一标识)
- 点击综合信息模块中的应用图标,并且上传一张可爱的图片(否则注册不了)
5、如图五:【权限管理】如果要实现上述过程需要申请如下API权限
6、如图六:点击上方【创建版本】并添加版本号及说明
7、如图七:点击【版本管理与发布】,点击【申请线上发布】
8、如图八:回到主页看到机器人状态为已启用及发布成功
250px|700px|reset

250px|700px|reset
250px|700px|reset

250px|700px|reset
四、添加机器人权限
1、新建一个存放周报数据的飞书表格、以及飞书文档
2、更多-添加文档应用-搜索自己的机器人名称-设置为可编辑-添加(表格、文档同一操作)
250px|700px|reset
👍恭喜你、至此你已经完成了所有机器人相关的准备工作!
五、实现流程及必要参数
250px|700px|reset
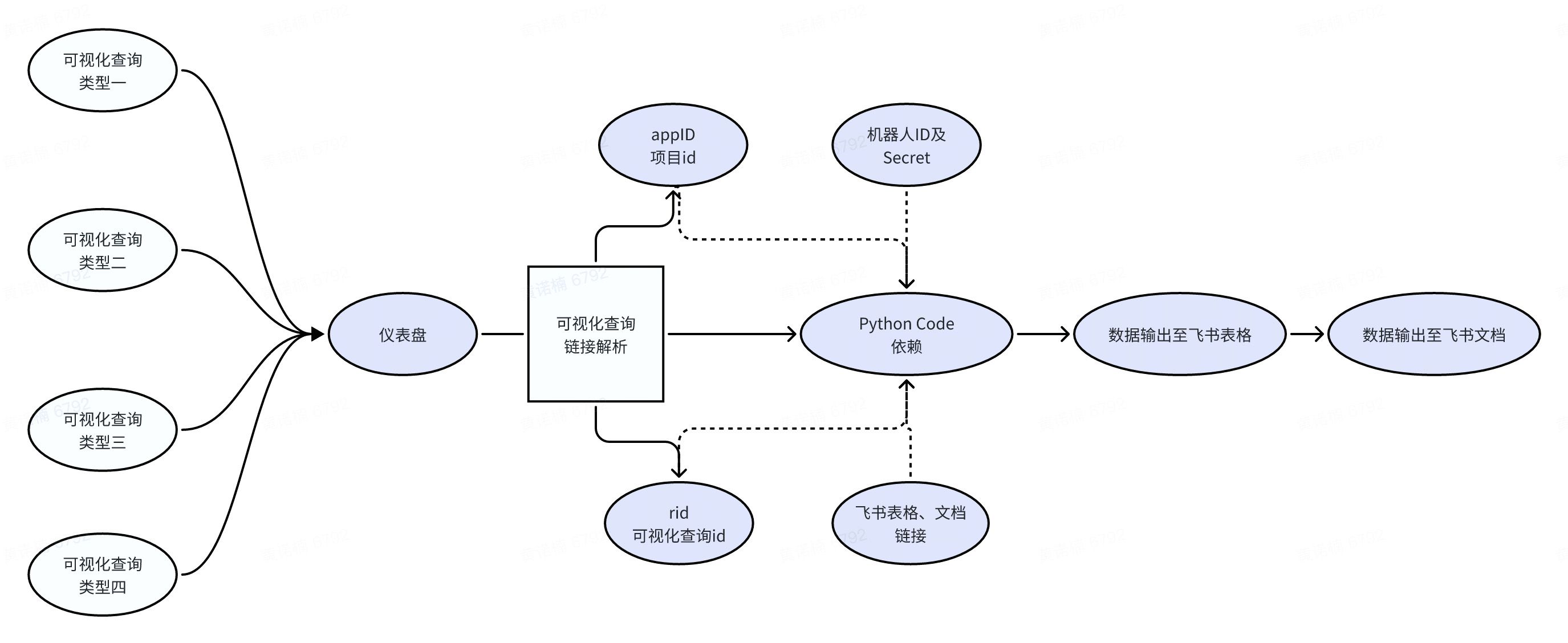
说明:上述图中仪表盘为可视化查询链接的存储载体,最为关键的是如何设计可视化查询链接,我过往的经历中总共遇到4种不同的可视化查询类型,如果有除了上述四种类型之外的可以联系我来在代码中新增处理函数。
🌟核心Python代码需要依赖的参数有:项目ID、可视化查询id、机器人APPID、机器人APP Secret、飞书表格链接、飞书文档链接。下面会一一举例说明所需链接在如何获取。
- 首先一个可视化查询中包含了项目id和可视化查询id
- 比如:aeolus-va.bytedance.net这个可视化查询链接中包含的appID为555771,rid为1907401,这两个id就是我们识别这个可视化查询的参数
- 机器人APPID、APP Secret在本文第三部分已经说明
- 飞书表格链接中包含了两部分:一部分为表格唯一标识,一部分为sheet唯一标识。
- 比如: XXXXXX/sheets/W7L7s6UM6hPhvPtLy7ocBjxInFd?sheet=fcd540 这个飞书表格中包含的表格参数为W7L7s6UM6hPhvPtLy7ocBjxInFd,sheet参数为fcd540。
- 飞书文档链接:
- 比如:XXXXXX/docx/FdVzdxnSpoWp8GxiKlscJAqonvh 这个飞书文档的唯一标识参数为:FdVzdxnSpoWp8GxiKlscJAqonvh。
六、可视化查询数据类型
🌟这个环节是最重要的环节啦!我将为大家介绍常用的四种可视化查询类型(几乎覆盖98%的业务场景)
如果有其他的需求可以联系我来更新数据处理函数,当然如果你自己有能力更改也希望能够同步给我,并在此文档中新增更多的可视化查询类型。
👍重要说明:必看!!!
由于可视化查询中一般会包含日期这个字段(date类型/string类型),同时会包含一些指标类的数据(string类型),最后包含了我们要的纬度(即int/float类型,也是需要制作mini图的类型),但是当代码讲数据读入python内存中会根据字段的首字母进行排序,因此请务必想办法将数字类指标放在最前面,其次是指标类数据,最后是日期类数据,因此需要通过重命名对可视化查询中的字段进行排序。
(如果上面的看不懂,也不要着急,后面我会详细说明)
6.1 可视化查询类型一
可视化查询类型一说明:
类型一为表格类型
特点:
- 只有一个纬度且一定为时间周期
- 可以有一个至多个指标,每个指标相互独立
排序说明:展示的位置并不能作为自动化处理后的排序,因此需要对指标按照您想要的顺序进行重命名
筛选器说明:筛选器不会被读入到python中,所以按需求任意筛选即可
注意由于代码无法对于不同的时间周期纬度进行对于,因此需要多所有时间周期纬度进行重命名,我是用Week来命名的。
6.2 可视化查询类型二
可视化查询类型二说明:
类型二为透视表类型
特点:
- 包含行、列、指标
- 行必须只有一个纬度,且一定为时间周期
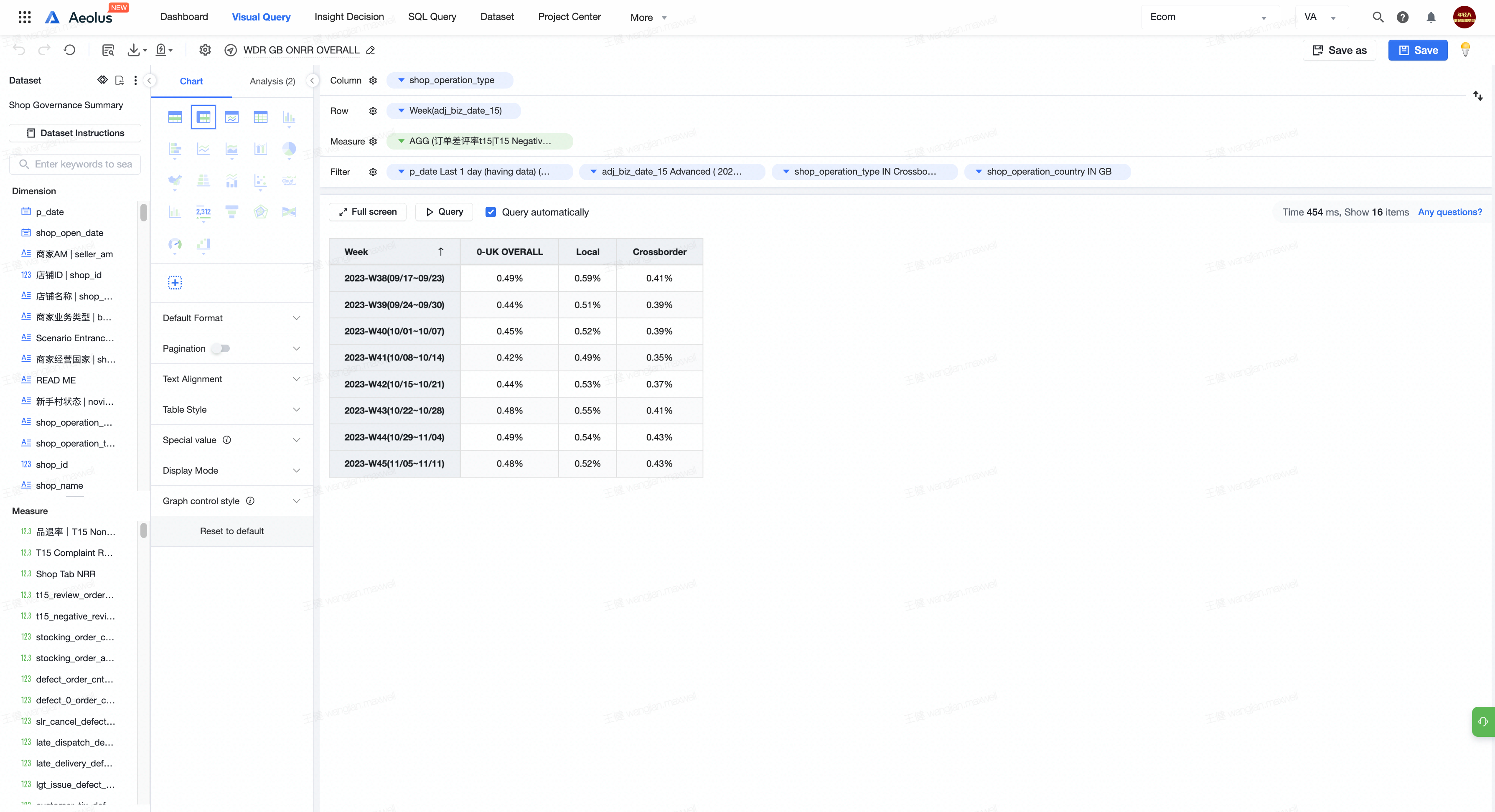
- 列必须只有一个纬度,这个纬度一定包含了多个字段。比如左图的shop_operation_type包含了Local和Crossborder
- 指标必须只有一个
排序说明:
- 这里需要注意需要将指标重命名为0_XX,列重命名为1_XX,剩下的一个已经被命名为Week了,即唯一时间标识,就不用重命名了。
筛选器说明:筛选器不会被读入到python中,所以按需求任意筛选即可
注意由于代码无法对于不同的时间周期纬度进行对于,因此需要多所有时间周期纬度进行重命名,我是用Week来命名的。
250px|700px|reset
250px|700px|reset
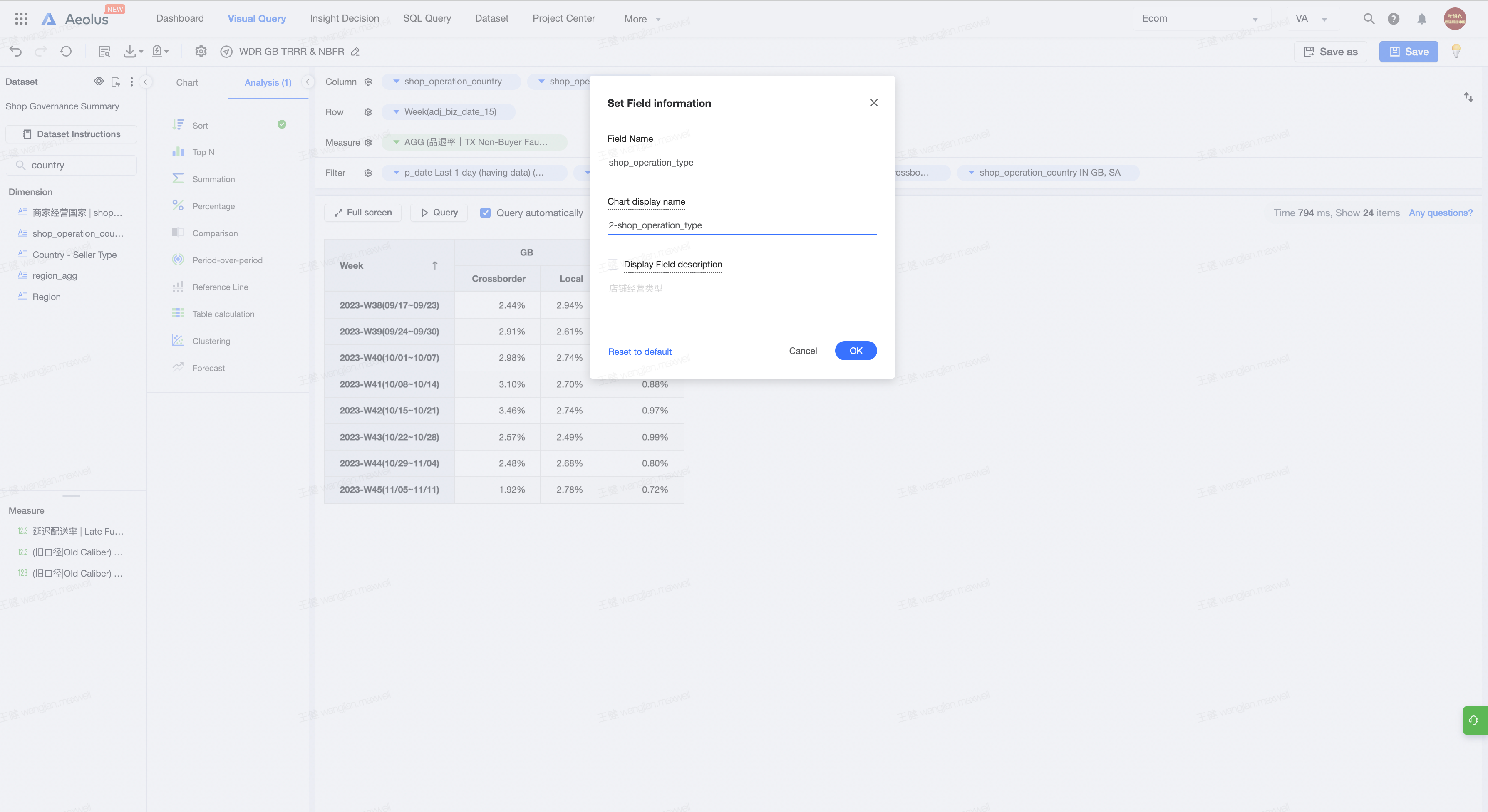
6.3 可视化查询类型三
可视化查询类型三说明:
- 类型三为透视表类型
- 特点:
- 包含行、列、指标
- 行必须只有一个纬度,且一定为时间周期
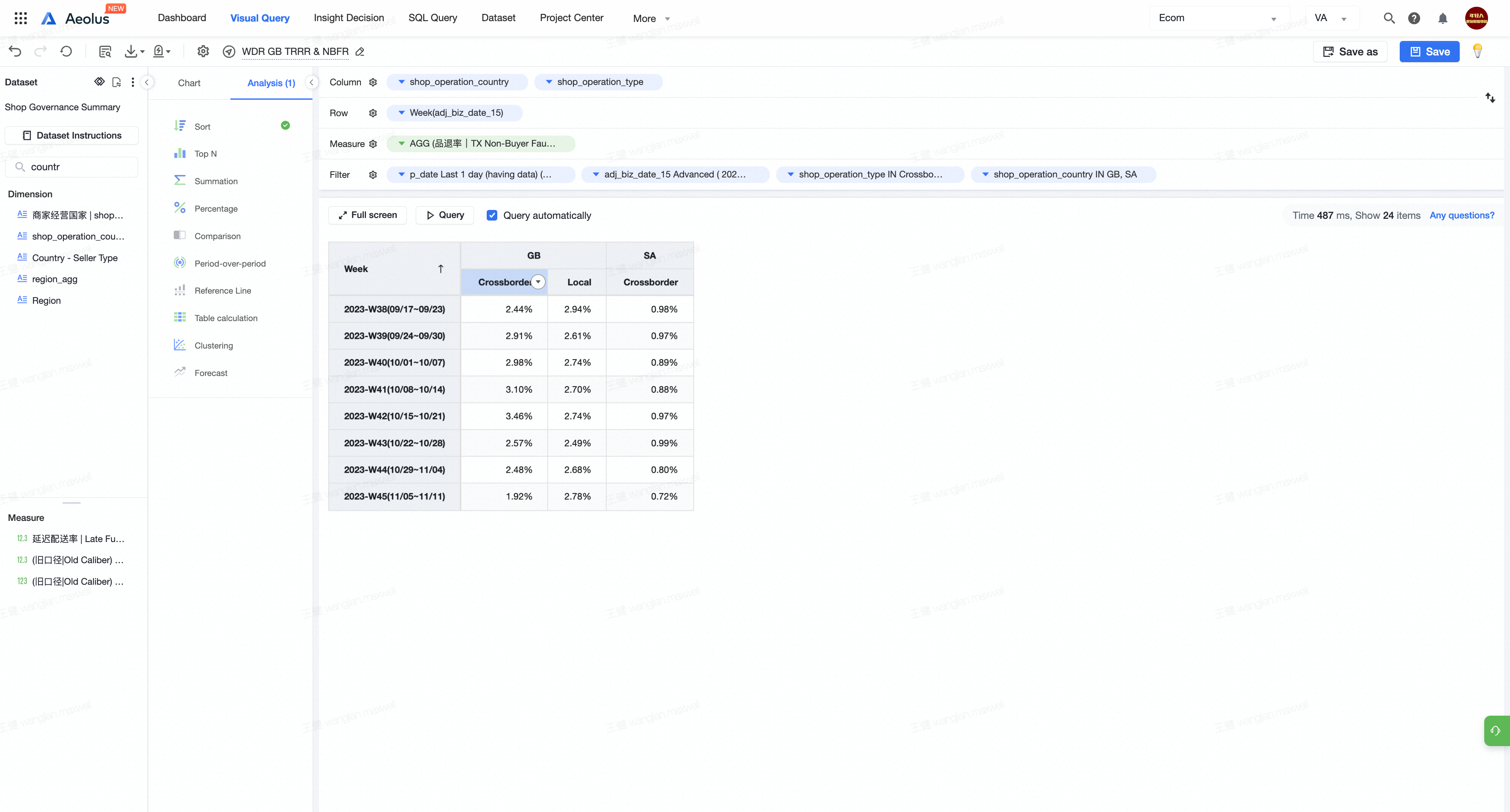
- 列必须有多于一个纬度,且这个纬度一定包含了多个字段(如果只有一个字段那么直接放入筛选器后用类型二就可以了)。比如左图的shop_operation_country包含了GB和SA,shop_operation_type包含了Local和Crossborder
- 指标必须只有一个(指标多于一个请看类型四)
- 排序说明:
- 这里需要注意需要将指标重命名为0_XX,列重命名为1_XX,2_XX,剩下的一个已经被命名为Week了,即唯一时间标识,就不用重命名了。
- 筛选器说明:筛选器不会被读入到python中,所以按需求任意筛选即可
- 注意由于代码无法对于不同的时间周期纬度进行对于,因此需要多所有时间周期纬度进行重命名,我是用Week来命名的。
250px|700px|reset
250px|700px|reset
250px|700px|reset
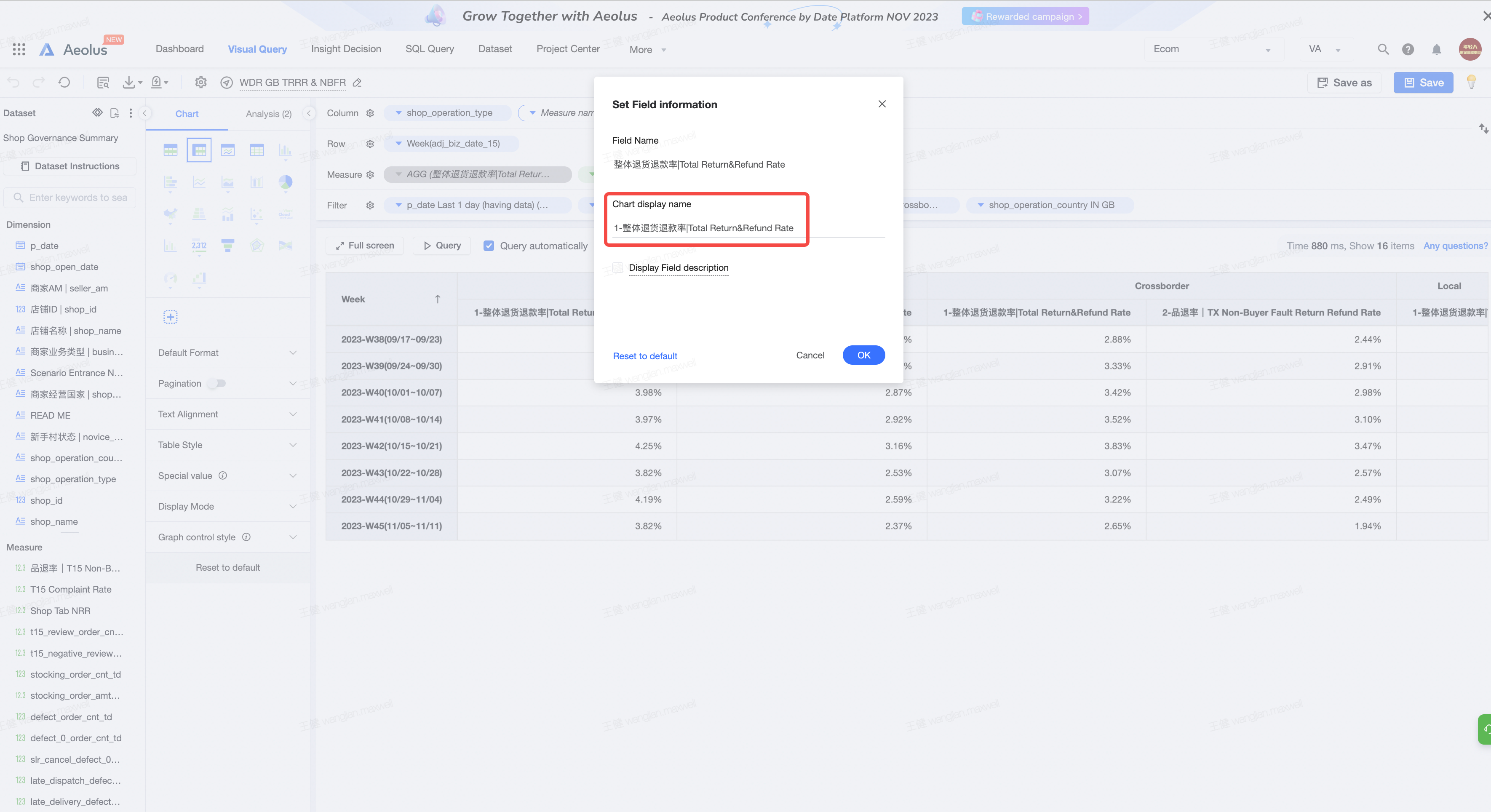
6.4 可视化查询类型四
可视化查询类型四说明:
类型四为透视表类型
特点:
- 包含行、列、指标
- 行必须只有一个纬度,且一定为时间周期
- 列必须有多于一个纬度,且这个纬度一定包含了多个字段(如果只有一个字段那么直接放入筛选器后用类型二就可以了)
- 指标必须多于一个
排序说明:
- 这里需要注意需要将指标重命名为0_XX,1_XX,列重命名为2_XX,剩下的一个已经被命名为Week了,即唯一时间标识,就不用重命名了。同时由于选择了多于一个指标,会在列上出现Measure Name字段,不用管,也不用重命名。
筛选器说明:筛选器不会被读入到python中,所以按需求任意筛选即可
注意由于代码无法对于不同的时间周期纬度进行对于,因此需要多所有时间周期纬度进行重命名,我是用Week来命名的。
250px|700px|reset

250px|700px|reset
七、可视化查询json配置
🌟上面已经说过了目前遇到的四种可视化查询数据类型,那么如何批量管理这么多的可视化查询呢?
1、可视化查询均另存在自己的仪表盘中
2、通过一个json来管理这些可视化查询
7.1 json 格式说明
js={
"WDR GB ONRR OVERALL":{
"project_id":"555771",
"rid":"1907401",
"owner":"Louise Lin",
"data_type":"2",
"need_concat_num":"0",
"metrics_num":"0",
},
"WDR GB SHOPTAB ONRR":{
"project_id":"555771",
"rid":"1910282",
"owner":"Louise Lin",
"data_type":"1",
"need_concat_num":"0",
"metrics_num":"0",
}
}
以上是包含两个可视化查询的json文件,每个可视化查询包含的必要参数如下。
7.2 json 参数说明
备注:类型一参数必定为:1 , 0, 0 。类型二参数必定为:2 ,0,0。(0为默认不需要的参数)
八、飞书表格的细节要求
250px|700px|reset
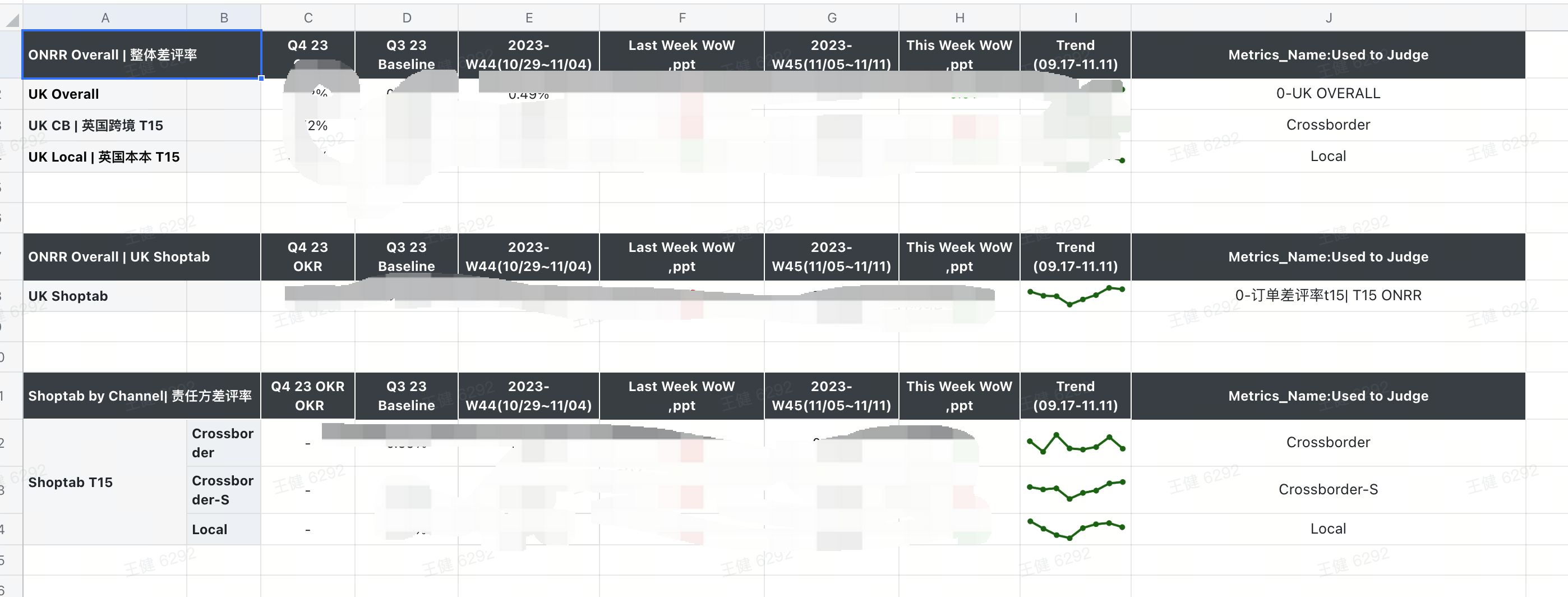
对于飞书表格有几点细节要求:
1、如图,在做自动化前需要明确数据插入的具体列:我是将数据插入至E:J列,如果需要更改请在代码中搜索更改。每一个table对应的是一个可视化查询链接,可视化查询链接有多少数据就对应几行。
(ps:最后一列J列是为了判断C和D列的数据是否粘贴错误的,单纯的串行)
2、每两个表格之间的间隔为2行,这个在代码中写死了,有需要自己改
3、A:D列的OKR或者你的其他线下数据需要自己手动填写(神仙也没办法)
九、飞书文档的细节要求
对于飞书文档有几点细节要求:
1、如图,将飞书表格中已经做好的每个表格直接粘贴到doc文档中作为模板(以我为例子,J列不用粘贴,代码中已经处理好不粘贴最后的J列了)
2、位置需要按照飞书表格中的顺序粘贴,但是每个表之间的标题,文本都不影响。
3、建议每次执行完代码,数据插入至文档中后,将此文档复制一份出来作为周会文档以保证此文档的id不变。简单来说这个文档是作为母版使用的。









